Convert PySpark to Glue Studio
2023年03月02日
After some investigation, I found it inappropriate to wrap it and place in Glue. And it would be suitable to use Glue native methods. I will demonstrate as below.
First, upload the source data u.data into an S3 bucket.
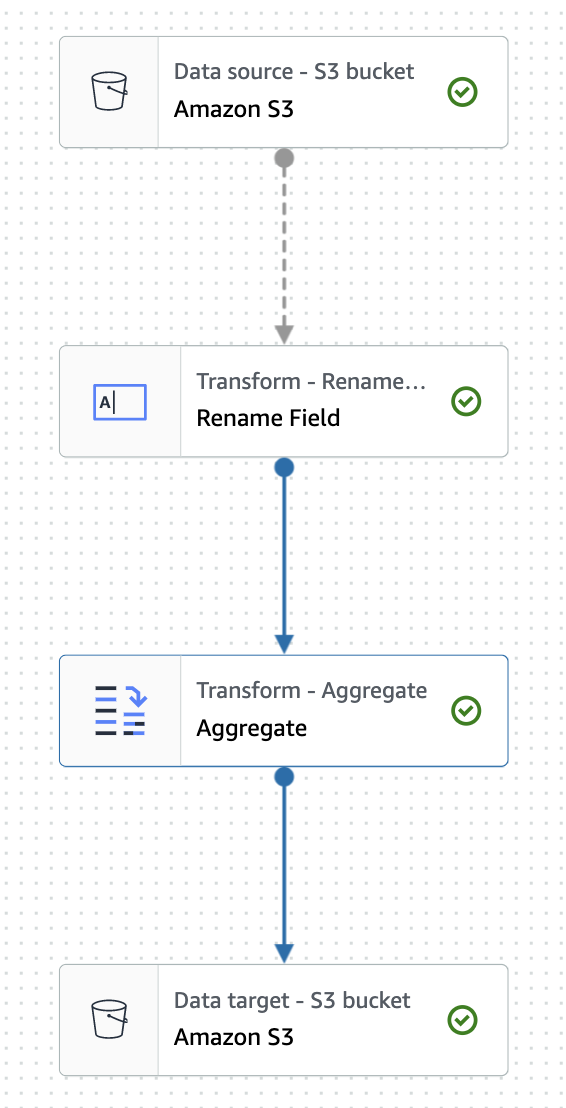
Orchestrate the ETL steps:
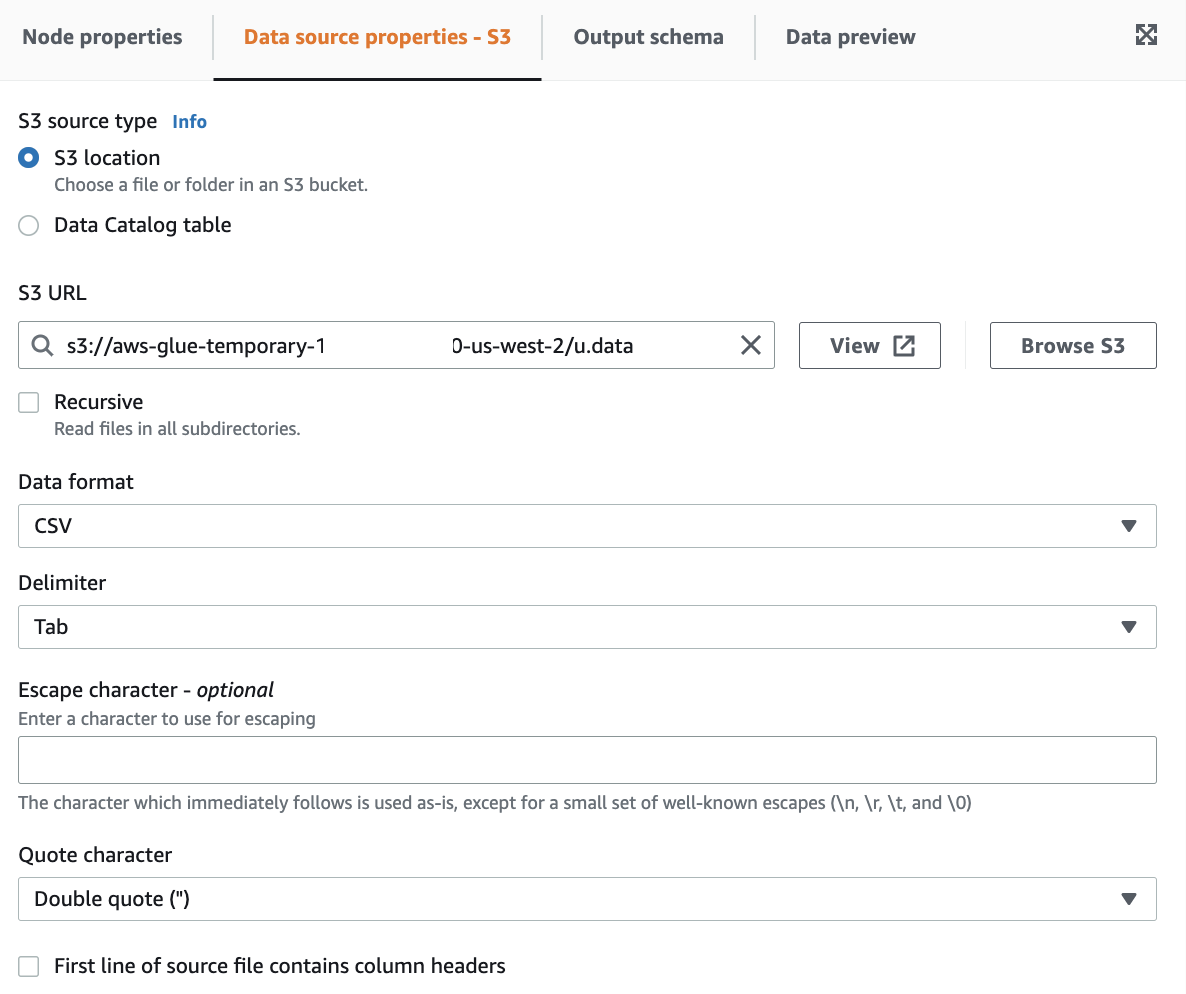
Source S3:
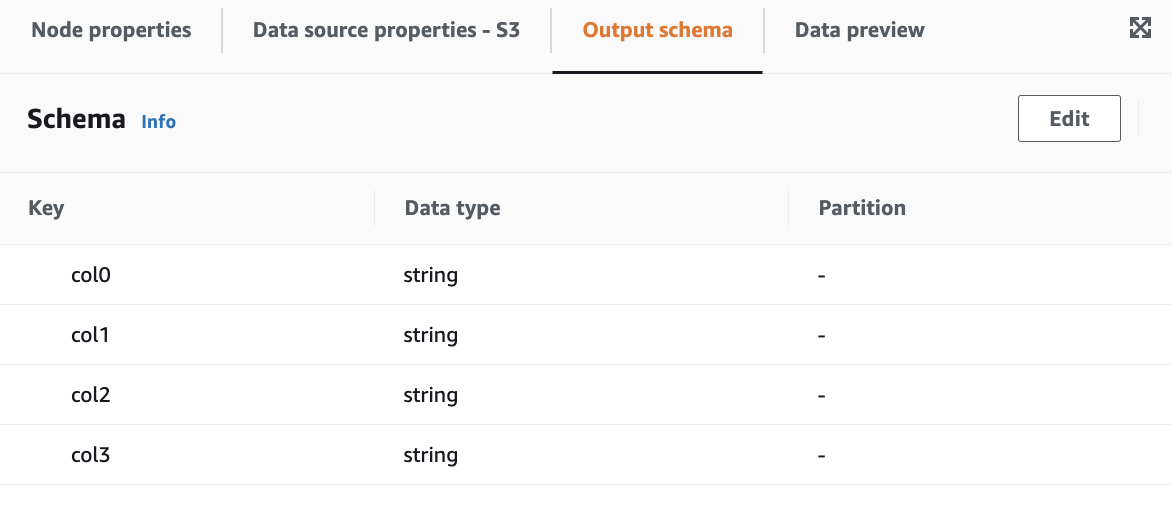
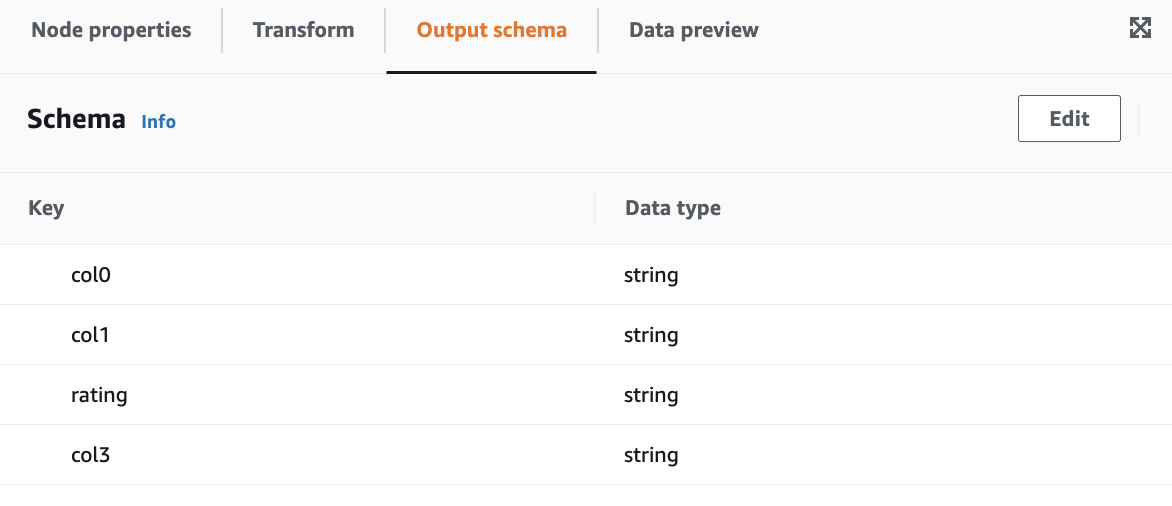
Output schema
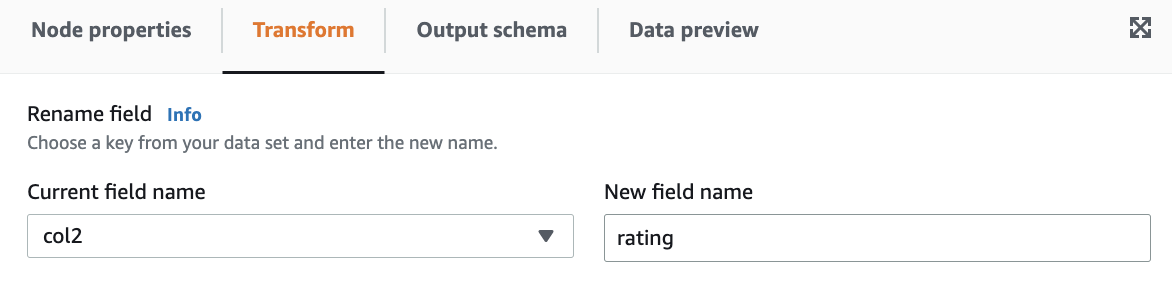
Rename field:
Output schema
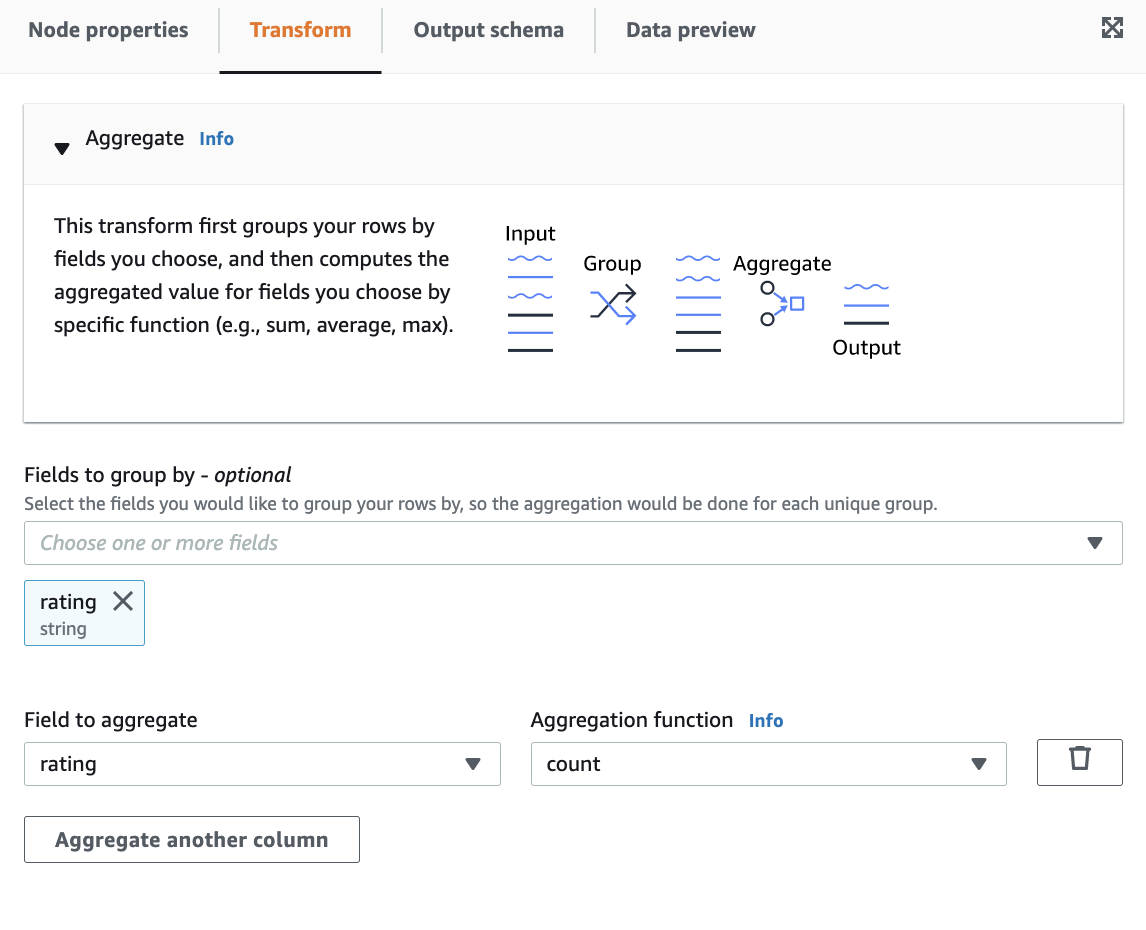
Group by and then Aggregate.
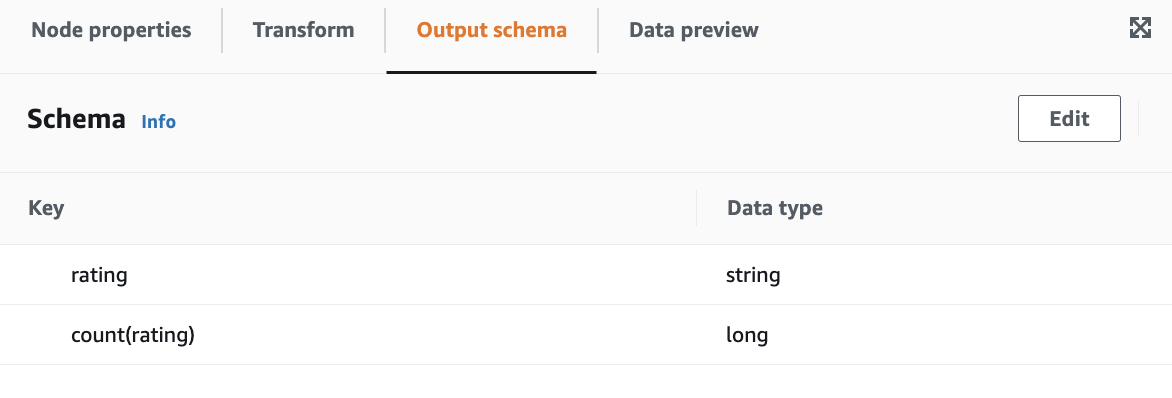
Output schema
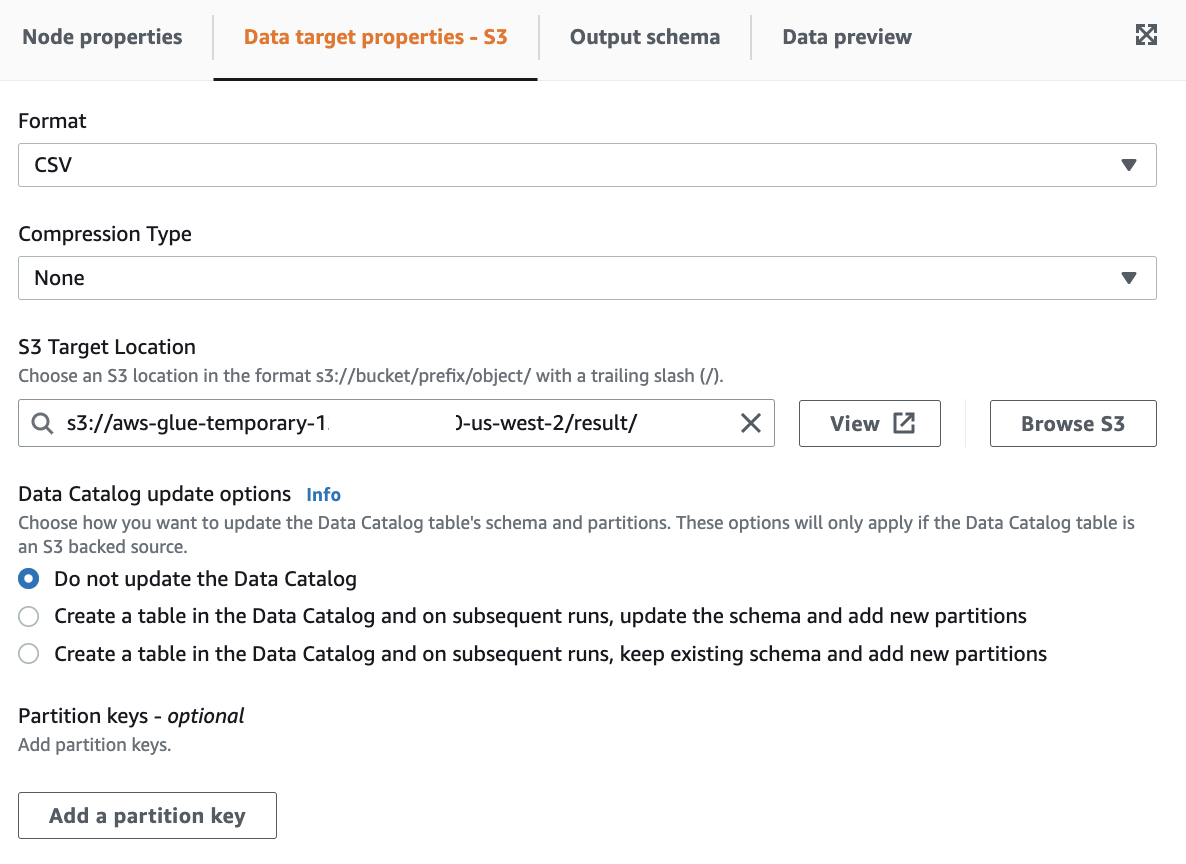
Target S3:
Output schema同上。
Save and run the job.
There are 36 output files appeared under the S3 bucket, , among them, below outputs are we really need.
File 1 content:
File 2:
File 3:
File 4:
File 5:
Appendix
The overall generated script:
-
I was thinking converting below simple PySpark into an AWS Glue job. Below PySpark is based on a previous post in Spark - Map example (that blog post has not been published to public yet).
import collections
import os
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("RatingsHistogram")
sc = SparkContext(conf=conf)
file = os.path.dirname(os.path.abspath(__file__)) + '/ml-100k/u.data'
lines = sc.textFile("file://"+file)
ratings = lines.map(lambda x: x.split()[2])
result = ratings.countByValue()
result_sorted = sorted(result.items())
sortedResults = collections.OrderedDict(result_sorted)
for key, value in sortedResults.items():
print("%s %i" % (key, value))
After some investigation, I found it inappropriate to wrap it and place in Glue. And it would be suitable to use Glue native methods. I will demonstrate as below.
First, upload the source data u.data into an S3 bucket.
Orchestrate the ETL steps:
Source S3:
Output schema
Rename field:
Output schema
Group by and then Aggregate.
Output schema
Target S3:
Output schema同上。
Save and run the job.
There are 36 output files appeared under the S3 bucket, , among them, below outputs are we really need.
File 1 content:
rating,"count(rating)" 1,6110
File 2:
rating,"count(rating)" 2,11370
File 3:
rating,"count(rating)" 3,27145
File 4:
rating,"count(rating)" 4,34174
File 5:
rating,"count(rating)" 5,21201Compared to the previous result when executing the PySpark in last post, they are the same. The Glue job's result is distributely stored in the S3 bucket.
Appendix
The overall generated script:
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.dynamicframe import DynamicFrame
from pyspark.sql import functions as SqlFuncs
def sparkAggregate(
glueContext, parentFrame, groups, aggs, transformation_ctx
) -> DynamicFrame:
aggsFuncs = []
for column, func in aggs:
aggsFuncs.append(getattr(SqlFuncs, func)(column))
result = (
parentFrame.toDF().groupBy(*groups).agg(*aggsFuncs)
if len(groups) > 0
else parentFrame.toDF().agg(*aggsFuncs)
)
return DynamicFrame.fromDF(result, glueContext, transformation_ctx)
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
# Script generated for node Amazon S3
AmazonS3_node1677724421448 = glueContext.create_dynamic_frame.from_options(
format_options={"quoteChar": '"', "withHeader": False, "separator": "\t"},
connection_type="s3",
format="csv",
connection_options={
"paths": ["s3://aws-glue-temporary-<111122223333>-us-west-2/u.data"],
"recurse": True,
},
transformation_ctx="AmazonS3_node1677724421448",
)
# Script generated for node Rename Field
RenameField_node1677724837209 = RenameField.apply(
frame=AmazonS3_node1677724421448,
old_name="col2",
new_name="rating",
transformation_ctx="RenameField_node1677724837209",
)
# Script generated for node Aggregate
Aggregate_node1677724516125 = sparkAggregate(
glueContext,
parentFrame=RenameField_node1677724837209,
groups=["rating"],
aggs=[["rating", "count"]],
transformation_ctx="Aggregate_node1677724516125",
)
# Script generated for node Amazon S3
AmazonS3_node1677724545988 = glueContext.write_dynamic_frame.from_options(
frame=Aggregate_node1677724516125,
connection_type="s3",
format="csv",
connection_options={
"path": "s3://aws-glue-temporary-<111122223333>-us-west-2/result/",
"partitionKeys": [],
},
transformation_ctx="AmazonS3_node1677724545988",
)
job.commit()
-