Coursera - Neural Networks and Deep Learning - Week 4 - Section 1 - Deep Neural Networks
2025年01月17日
What is a deep neural network?
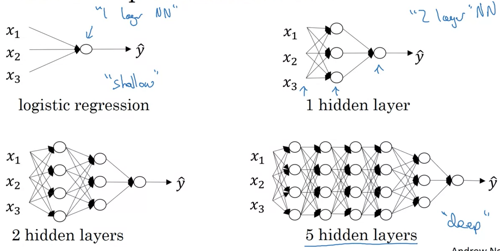
Deep neural network notation
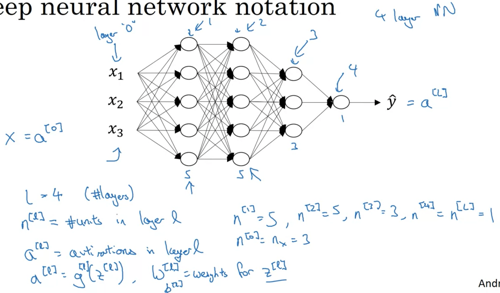
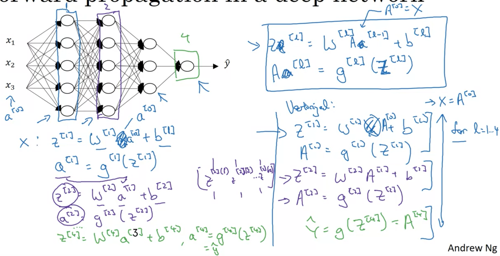
Forward propagation in a deep network
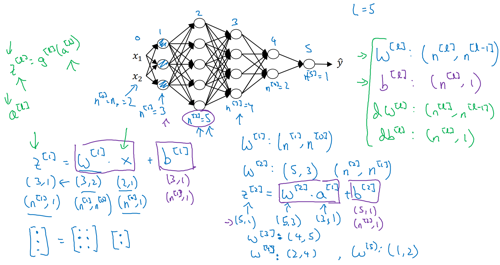
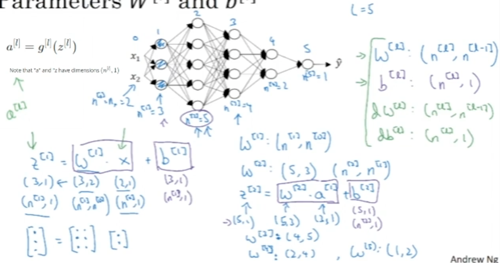
Parameters W[l] and b[l]
-
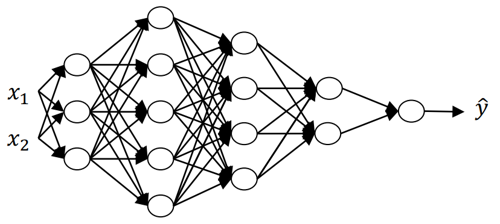
Vectorized implementation
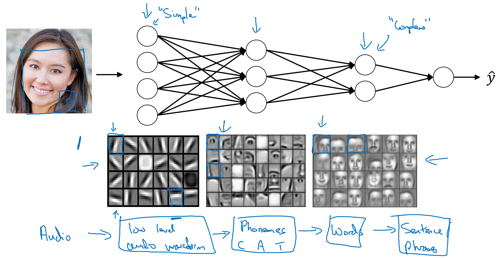
Intuition about deep representation
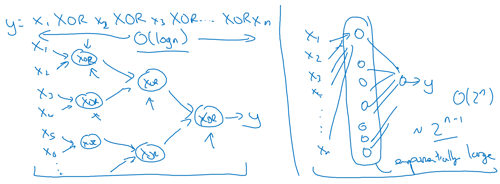
Circuit theory and deep learning
Informally: There are functions you can compute with a "small" L-layer deep neural network that shallower networks require exponentially more hidden units to compute.
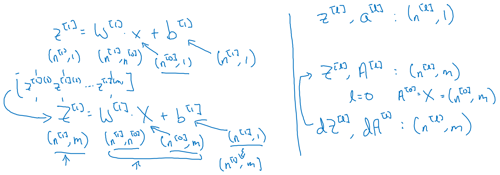
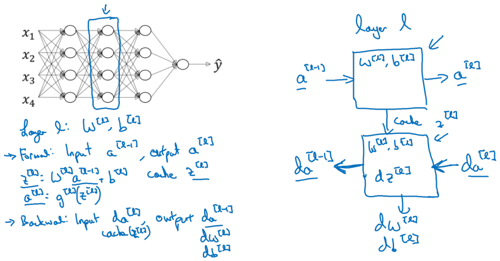
Forward and backward functions
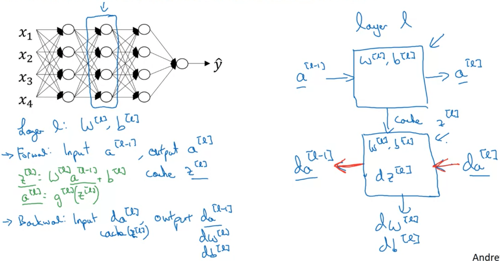
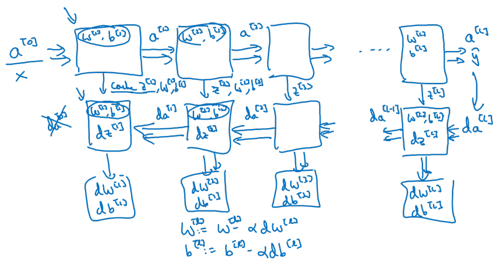
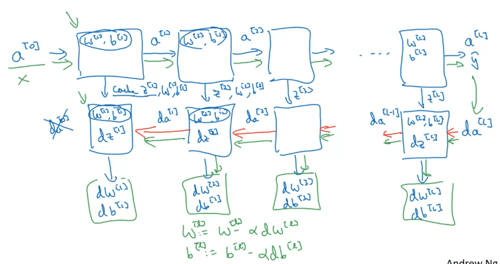
Forward propagation for layer l
Input a[l-1]
Output a[l], cache (z[l])
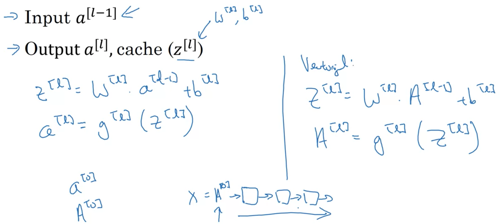
Backward propagation for layer l
Input da[l]
Output da[l-1], dW[l], db[l]
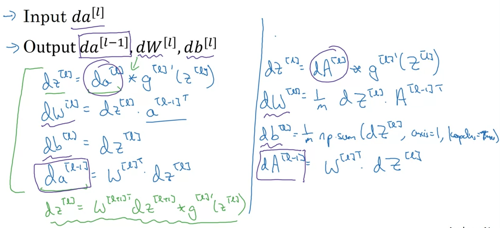
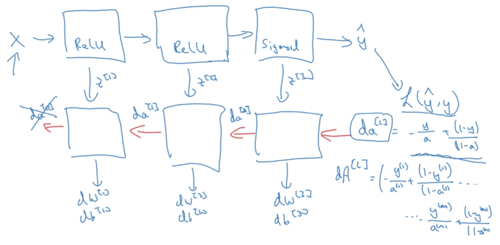
Summary
For a more in depth explaination of Feedforward Neural Networks, one of our DLS mentors has written some articles (optional reading) on them. If these interest you, do check them out.
A huge shoutout and thanks to Jonas Lalin!
What are hyperparameters?
Parameters: W[1], b[1], W[2], b[2], W[3], b[3] …


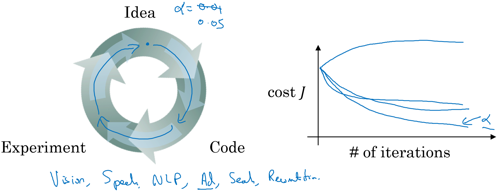
Applied deep learning is a very empirical process
Note that the formulas shown in the next video have a few typos. Here is the correct set of formulas.dZ[L]=A[L]−YdZ[L]=A[L]−YdW[L]=1mdZ[L]A[L−1]TdW[L]=m1dZ[L]A[L−1]Tdb[L]=1mnp.sum(dZ[L],axis=1,keepdims=True)db[L]=m1np.sum(dZ[L],axis=1,keepdims=True)dZ[L−1]=W[L]TdZ[L]∗g′[L−1](Z[L−1])dZ[L−1]=W[L]TdZ[L]∗g′[L−1](Z[L−1])Note that * denotes element-wise multiplication)⋮⋮dZ[1]=W[2]TdZ[2]∗g′[1](Z[1])dZ[1]=W[2]TdZ[2]∗g′[1](Z[1])dW[1]=1mdZ[1]A[0]TdW[1]=m1dZ[1]A[0]TNote that A[0]TA[0]T is another way to denote the input features, which is also written as XTXTdb[1]=1mnp.sum(dZ[1],axis=1,keepdims=True)db[1]=m1np.sum(dZ[1],axis=1,keepdims=True)
-
-
Forward and backward propagation
-

-
Week 4: Deep Neural Networks
Section 1: Deep Neural Network
1. Video: Deep L-layer Neural Network
What is a deep neural network?

Deep neural network notation

2. Video: Forward Propagation in a Deep Network
Forward propagation in a deep network

3. Video: Getting your Matrix Dimensions Right
Parameters W[l] and b[l]

-

Vectorized implementation


4. Video: Why Deep Representations?
Intuition about deep representation

Circuit theory and deep learning
Informally: There are functions you can compute with a "small" L-layer deep neural network that shallower networks require exponentially more hidden units to compute.

5. Video: Building Blocks of Deep Neural Networks
Forward and backward functions




6. Video: Forward and Backward Propagation
Forward propagation for layer l
Input a[l-1]
Output a[l], cache (z[l])

Backward propagation for layer l
Input da[l]
Output da[l-1], dW[l], db[l]

Summary

7. Reading: Optional Reading: Feedforward Neural Networks in Depth
For a more in depth explaination of Feedforward Neural Networks, one of our DLS mentors has written some articles (optional reading) on them. If these interest you, do check them out.
A huge shoutout and thanks to Jonas Lalin!
8. Video: Parameters vs Hyperparameters
What are hyperparameters?
Parameters: W[1], b[1], W[2], b[2], W[3], b[3] …


Applied deep learning is a very empirical process


9. Reading: Clarification For: What does this have to do with the brain?
-Note that the formulas shown in the next video have a few typos. Here is the correct set of formulas.dZ[L]=A[L]−YdZ[L]=A[L]−YdW[L]=1mdZ[L]A[L−1]TdW[L]=m1dZ[L]A[L−1]Tdb[L]=1mnp.sum(dZ[L],axis=1,keepdims=True)db[L]=m1np.sum(dZ[L],axis=1,keepdims=True)dZ[L−1]=W[L]TdZ[L]∗g′[L−1](Z[L−1])dZ[L−1]=W[L]TdZ[L]∗g′[L−1](Z[L−1])Note that * denotes element-wise multiplication)⋮⋮dZ[1]=W[2]TdZ[2]∗g′[1](Z[1])dZ[1]=W[2]TdZ[2]∗g′[1](Z[1])dW[1]=1mdZ[1]A[0]TdW[1]=m1dZ[1]A[0]TNote that A[0]TA[0]T is another way to denote the input features, which is also written as XTXTdb[1]=1mnp.sum(dZ[1],axis=1,keepdims=True)db[1]=m1np.sum(dZ[1],axis=1,keepdims=True)
-
-
10. Video: What does this have to do with the brain?
Forward and backward propagation
-

-