Integrate Splunk with AWS Kinesis Data Firehose
In this blog post, we will architect a logging transfer path to Splunk cloud. For illustration purpose, we will use VPC flow logs as log source data. The point is that AWS China Kinesis Firehose does not support Splunk as destination.
Important
The solution depicted in this post is only for deep diving the Firehose - Splunk solution. For production solution, we need to simplify the overall design, and try to remove ALB and Lambda from the architecture.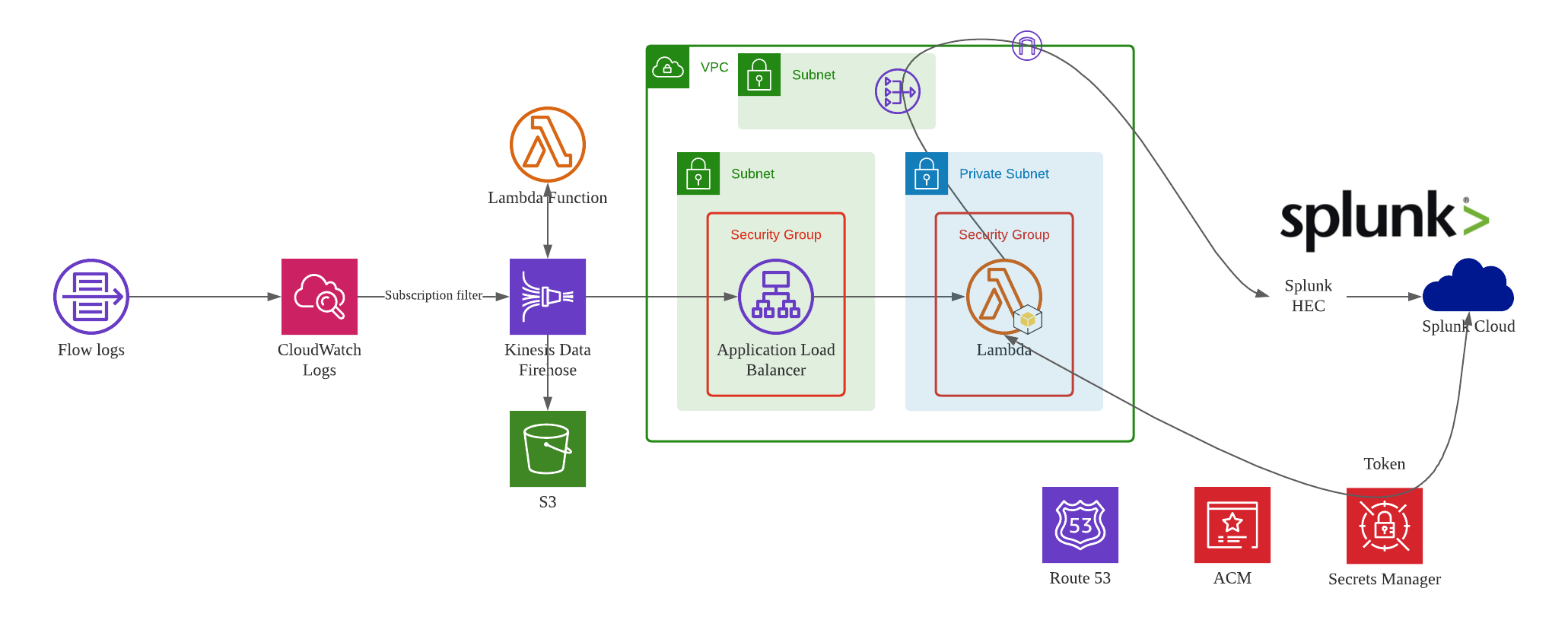
VPC delivers flow log files into a CloudWatch Logs group. Using a CloudWatch Logs subscription filter, we set up real-time delivery of CloudWatch Logs to an Kinesis Data Firehose stream.
Data coming from CloudWatch Logs is compressed with gzip compression. To work with this compression, we need to configure a Lambda-based data transformation in Kinesis Data Firehose to decompress the data and deposit it back into the stream. Firehose then delivers the raw logs to the Splunk Http Event Collector (HEC).
If delivery to the Splunk HEC fails, Firehose deposits the logs into an Amazon S3 bucket. You can then ingest the events from S3 using an alternate mechanism such as a Lambda function.
When data reaches Splunk (Enterprise or Cloud), Splunk parsing configurations (packaged in the Splunk Add-on for Kinesis Data Firehose) extract and parse all fields. They make data ready for querying and visualization using Splunk Enterprise and Splunk Cloud.
Login Splunk web console.
Install the Splunk Add-on for Amazon Kinesis Data Firehose
The Splunk Add-on for Amazon Kinesis Data Firehose enables Splunk (be it Splunk Enterprise, Splunk App for AWS, or Splunk Enterprise Security) to use data ingested from Kinesis Data Firehose.
Set up the Splunk HEC to receive the data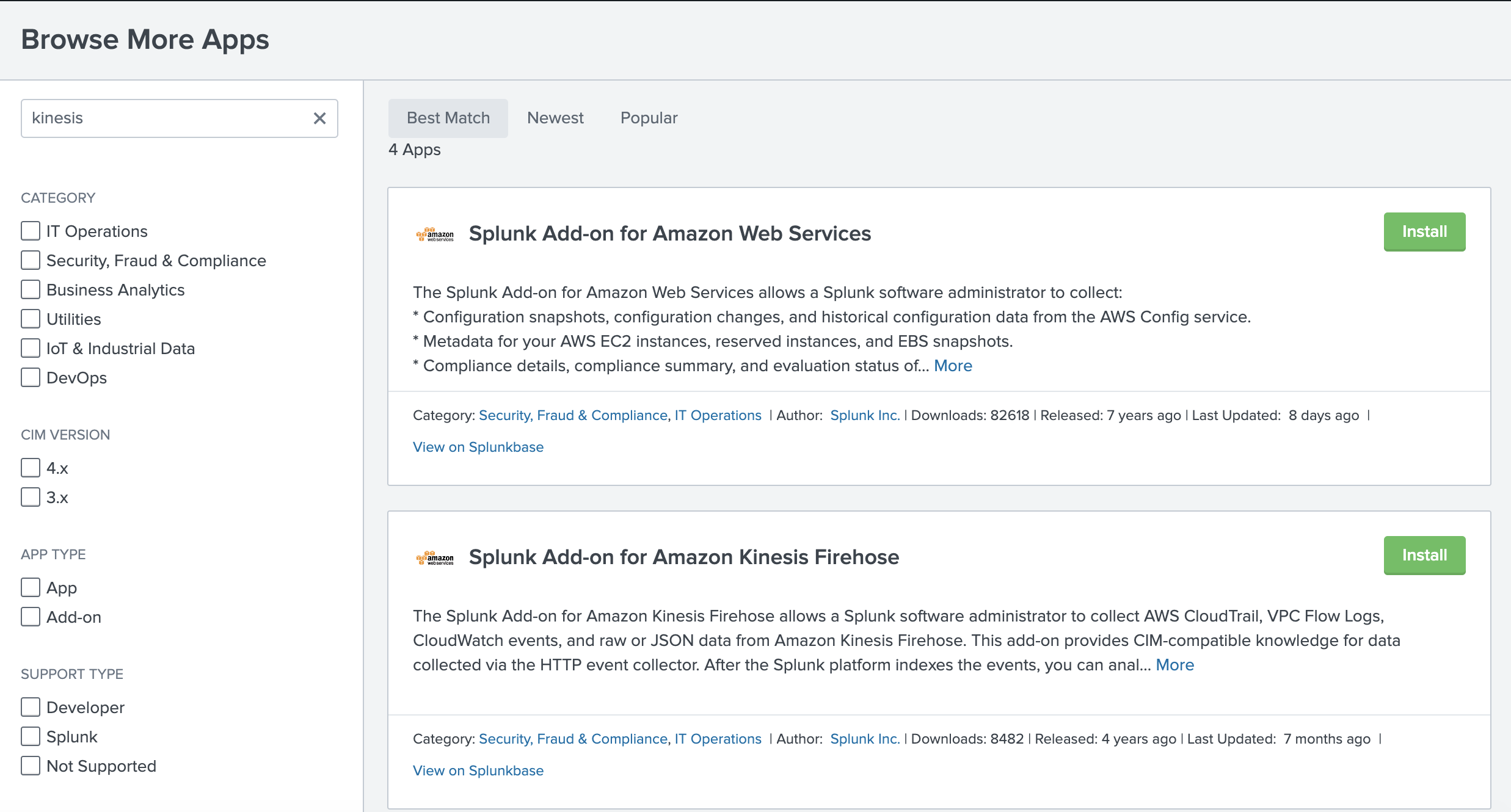
HTTP Event Collector (HEC)
Before you can use Kinesis Data Firehose to deliver data to Splunk, set up the Splunk HEC to receive the data.
From Splunk web, go to the Setting menu, choose Data Inputs, and choose HTTP Event Collector.
Go to the Setting menu, choose Data Inputs.
Click HTTP Event Collector.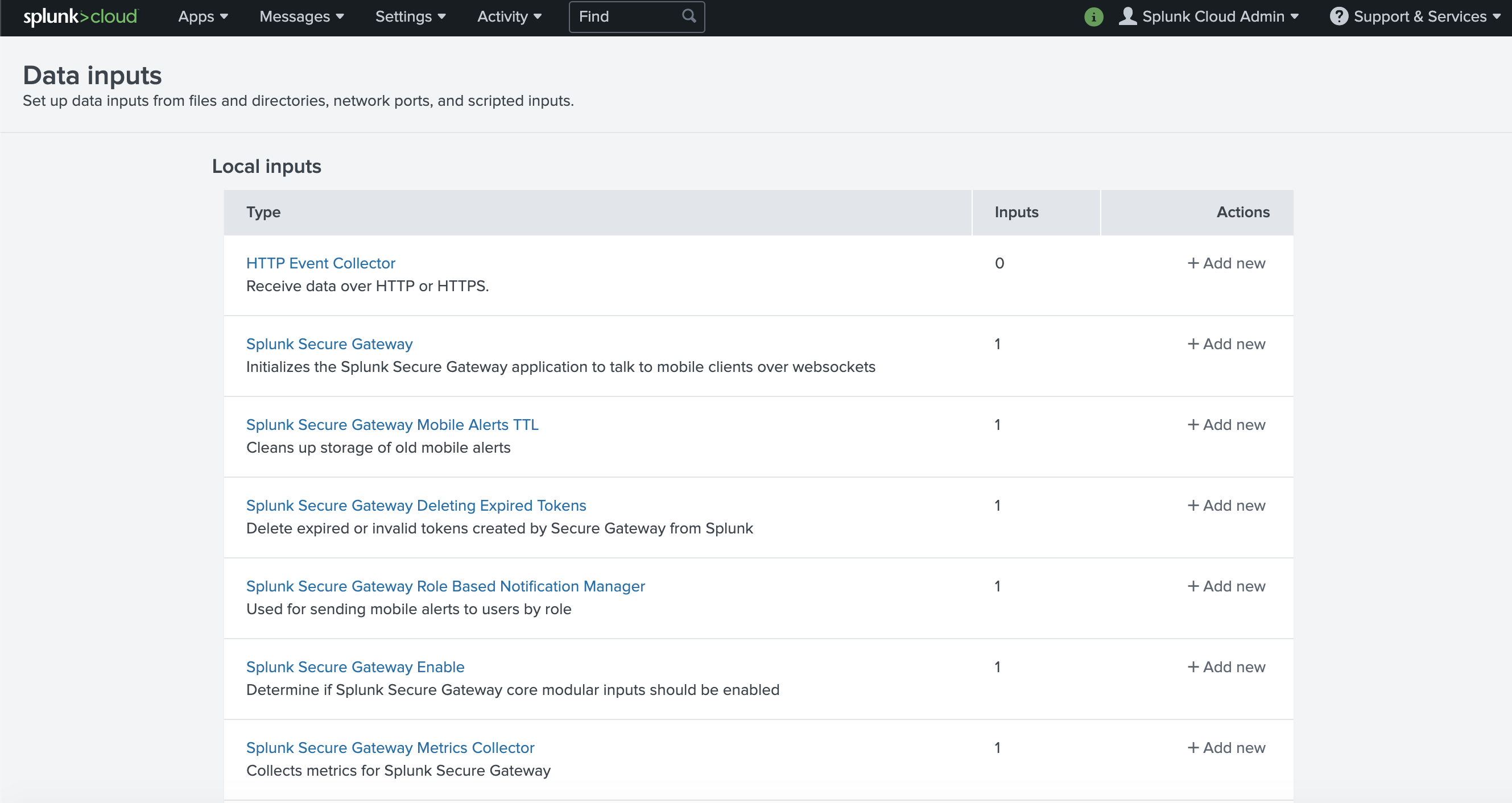
-
Choose Global Settings, ensure All tokens is enabled, and then choose Save.
Choose Global Settings.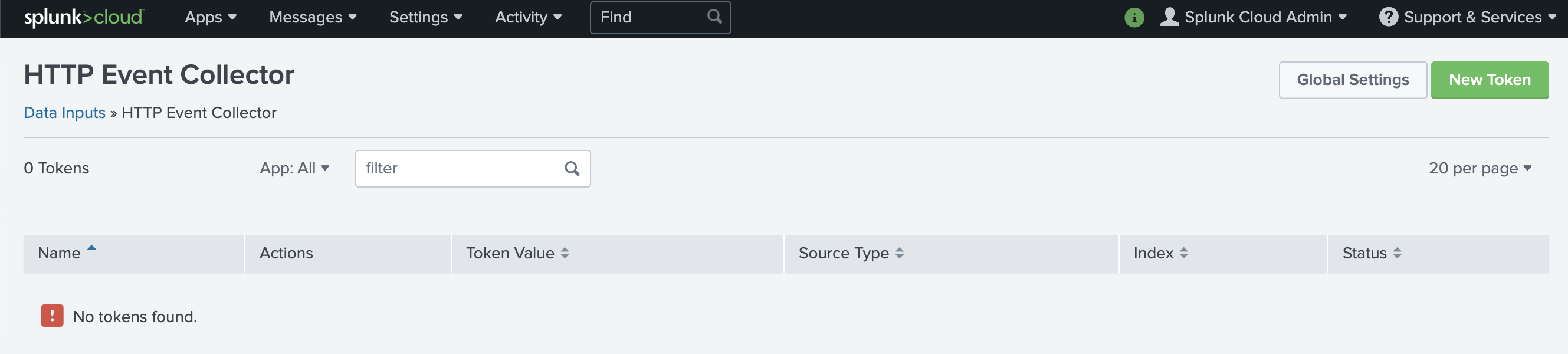
Ensure All Tokens is enabled.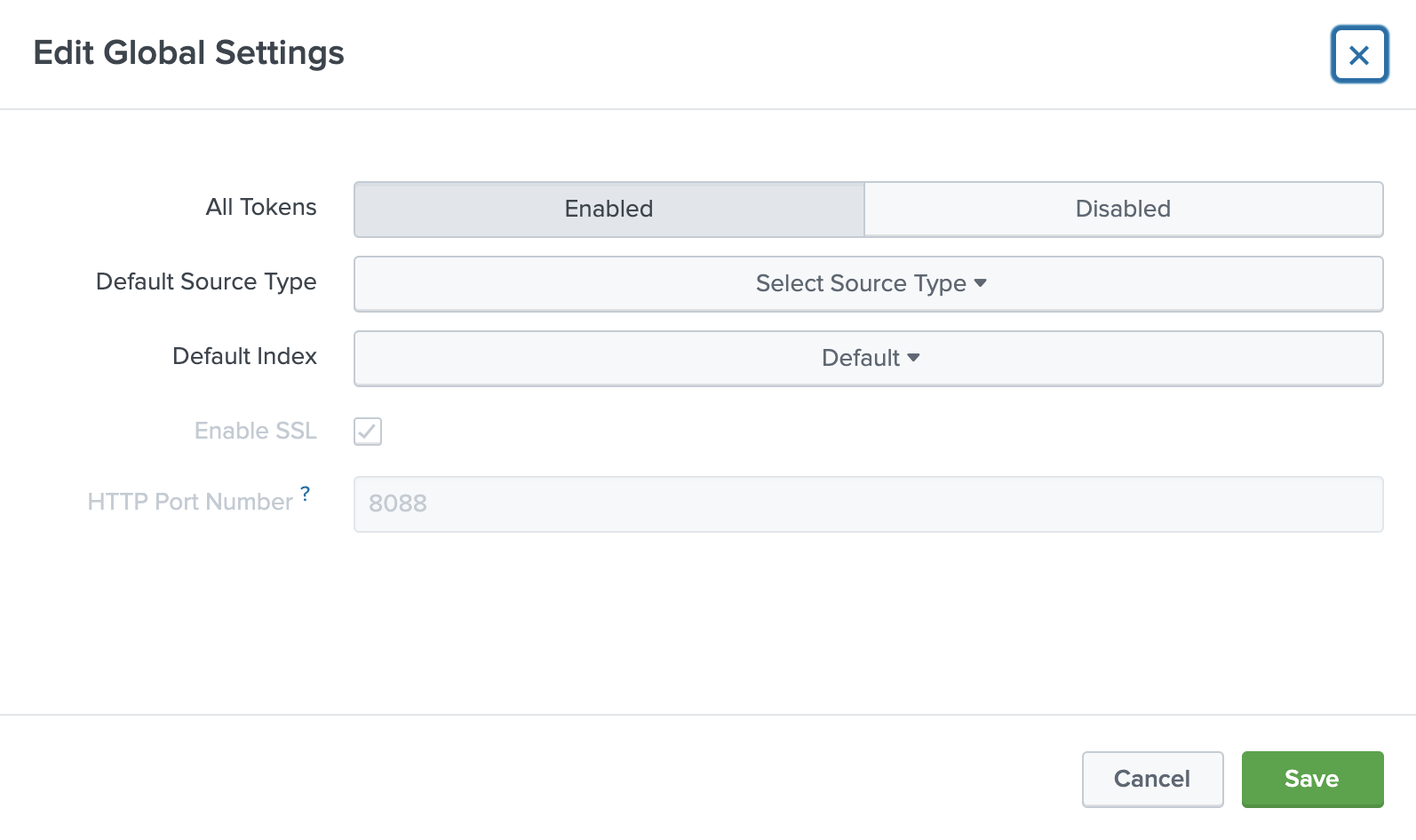
Choose Save.
Then choose New Token to create a new HEC endpoint and token. When you create a new token, make sure that Enable indexer acknowledgment is checked.
Choose New Token to create a new HEC endpoint and token.
When you create a new token, make sure that Enable indexer acknowledgment is checked.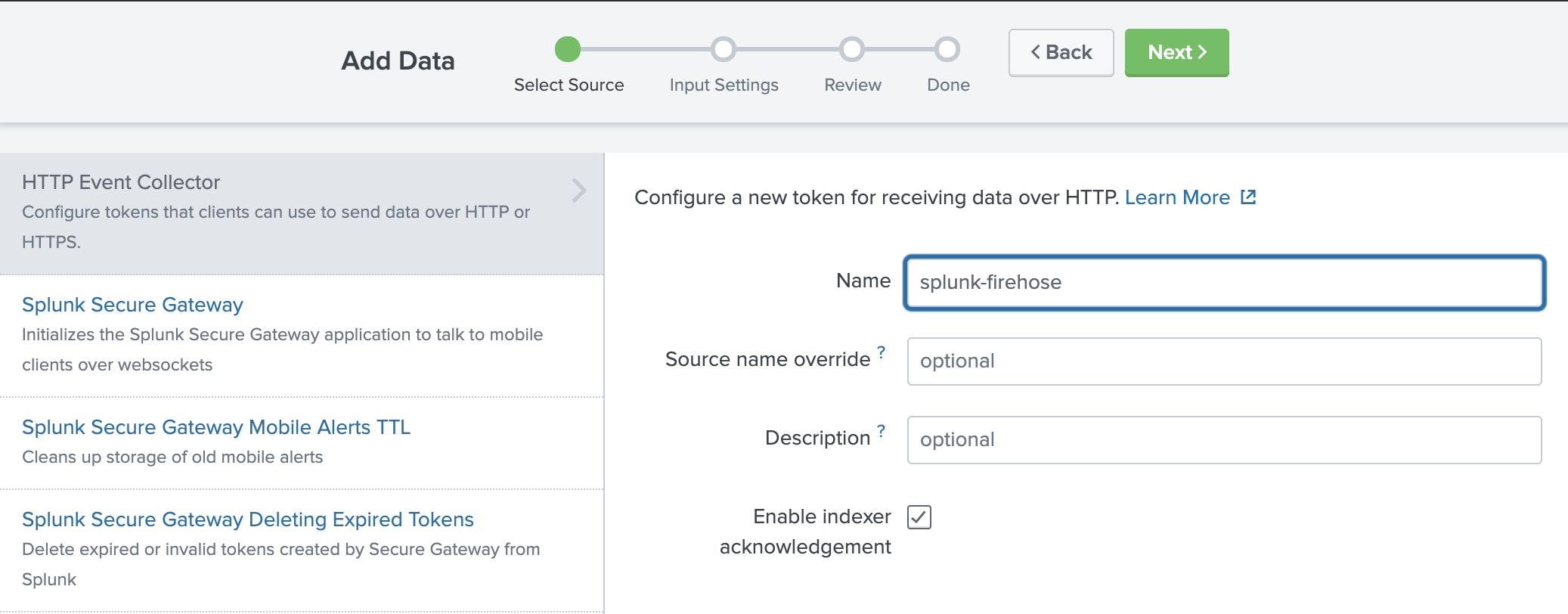
-
When prompted to select a source type, select aws:cloudwatch:vpcflow.
-
Create an S3 backsplash bucket
To provide for situations in which Kinesis Data Firehose can’t deliver data to the Splunk Cluster, we use an S3 bucket to back up the data. You can configure this feature to back up all data or only the data that’s failed during delivery to Splunk.
Note: Bucket names are unique. Thus, you can’t use tmak-backsplash-bucket.
aws s3 create-bucket --bucket tmak-backsplash-bucket --create-bucket-configuration LocationConstraint=ap-northeast-1
Create an IAM role for the Lambda transform function
Firehose triggers an AWS Lambda function that transforms the data in the delivery stream. Let’s first create a role for the Lambda function called LambdaBasicRole.
Note: You can also set this role up when creating your Lambda function.
aws iam create-role --role-name LambdaBasicRole --assume-role-policy-document file://TrustPolicyForLambda.json
TrustPolicyForLambda.json.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
After the role is created, attach the managed Lambda basic execution policy to it.
aws iam attach-role-policy --policy-arn arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole --role-name LambdaRoleFirehoseTransformation
Create Lambda function
Create a Lambda function to respond requests forwarded by ALB and transfer logs to Splunk cloud.
import base64
import json
import requests
def lambda_handler(event, context):
if isinstance(event["body"], str) and "" == event["body"]:
return {
'statusCode': 200,
'body': "Events generated by Load balancer performing health check",
"headers": {
'content-type': 'application/json'
}
}
body = json.loads(event["body"])
records = body["records"]
for each in records:
# decode base64 data
log = base64.b64decode(each["data"])
# TO-DO: generate X-Splunk-Request-Channel ID
resp = requests.post(
'https://inputs.prd-p-abcde.splunkcloud.com:8088/services/collector/raw',
data=log,
headers={
"Authorization": "Splunk xxxx-xx-xx-xx-xxxx",
"X-Splunk-Request-Channel": "xxxx-xx-xx-xx-xxxx"
},
verify=False
)
return {
'statusCode': 200,
'body': json.dumps(resp.text),
"headers": {
'content-type': 'application/json'
}
}
Create ACM Certificate
In ACM, request a new SSL/TLS certificate for the new domain name, e.g., example.tianzhui.cloud.
Create ALB
Create an ALB and configure the Lambda function as its backend. Associate the ACM certificate to the ALB.
Create Route 53 resolution
In Route 53, create a DNS resolution record to resolve ALB's DNS name to your own domain name, e.g., example.tianzhui.cloud.
The record type is A record. Enable Alias. Set the the traffic to be routed to the ALB.
IAM Role for Firehose
Create IAM policy. Here I name it as FirehosePolicy-VpcFlowLog2Splunk-uswest2. The policy gives Kinesis Data Firehose permission to publish error logs to CloudWatch, execute your Lambda function, and put records into your S3 backup bucket.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Action": [
"glue:GetTable",
"glue:GetTableVersion",
"glue:GetTableVersions"
],
"Resource": [
"arn:aws:glue:us-west-2:123456789012:catalog",
"arn:aws:glue:us-west-2:123456789012:database/%FIREHOSE_POLICY_TEMPLATE_PLACEHOLDER%",
"arn:aws:glue:us-west-2:123456789012:table/%FIREHOSE_POLICY_TEMPLATE_PLACEHOLDER%/%FIREHOSE_POLICY_TEMPLATE_PLACEHOLDER%"
]
},
{
"Sid": "",
"Effect": "Allow",
"Action": [
"s3:AbortMultipartUpload",
"s3:GetBucketLocation",
"s3:GetObject",
"s3:ListBucket",
"s3:ListBucketMultipartUploads",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::s***-us-west-2",
"arn:aws:s3:::s***-us-west-2/*"
]
},
{
"Sid": "",
"Effect": "Allow",
"Action": [
"lambda:InvokeFunction",
"lambda:GetFunctionConfiguration"
],
"Resource": "arn:aws:lambda:us-west-2:124011853020:function:FirehoseSplunkTransformVPC:$LATEST"
},
{
"Effect": "Allow",
"Action": [
"kms:GenerateDataKey",
"kms:Decrypt"
],
"Resource": [
"arn:aws:kms:us-west-2:123456789012:key/%FIREHOSE_POLICY_TEMPLATE_PLACEHOLDER%"
],
"Condition": {
"StringEquals": {
"kms:ViaService": "s3.us-west-2.amazonaws.com"
},
"StringLike": {
"kms:EncryptionContext:aws:s3:arn": [
"arn:aws:s3:::%FIREHOSE_POLICY_TEMPLATE_PLACEHOLDER%/*"
]
}
}
},
{
"Sid": "",
"Effect": "Allow",
"Action": [
"logs:PutLogEvents"
],
"Resource": [
"arn:aws:logs:us-west-2:123456789012:log-group:/aws/kinesisfirehose/FirehoseSplunkDeliveryStream:log-stream:*"
]
},
{
"Sid": "",
"Effect": "Allow",
"Action": [
"kinesis:DescribeStream",
"kinesis:GetShardIterator",
"kinesis:GetRecords",
"kinesis:ListShards"
],
"Resource": "arn:aws:kinesis:us-west-2:123456789012:stream/%FIREHOSE_POLICY_TEMPLATE_PLACEHOLDER%"
},
{
"Effect": "Allow",
"Action": [
"kms:Decrypt"
],
"Resource": [
"arn:aws:kms:us-west-2:123456789012:key/%FIREHOSE_POLICY_TEMPLATE_PLACEHOLDER%"
],
"Condition": {
"StringEquals": {
"kms:ViaService": "kinesis.us-west-2.amazonaws.com"
},
"StringLike": {
"kms:EncryptionContext:aws:kinesis:arn": "arn:aws:kinesis:us-west-2:123456789012:stream/%FIREHOSE_POLICY_TEMPLATE_PLACEHOLDER%"
}
}
}
]
}
Create a new IAM role for the Firehose stream. Give the role a name, as FirehoseRoleVpcFlowLog, and then choose Allow. Attach policy document FirehosePolicy-VpcFlowLog2Splunk-uswest2 to this role.
Trust relationships of this role:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "firehose.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
Create a Firehose Stream
On the AWS console, open the Amazon Kinesis service, go to the Firehose console, and choose Create Delivery Stream.
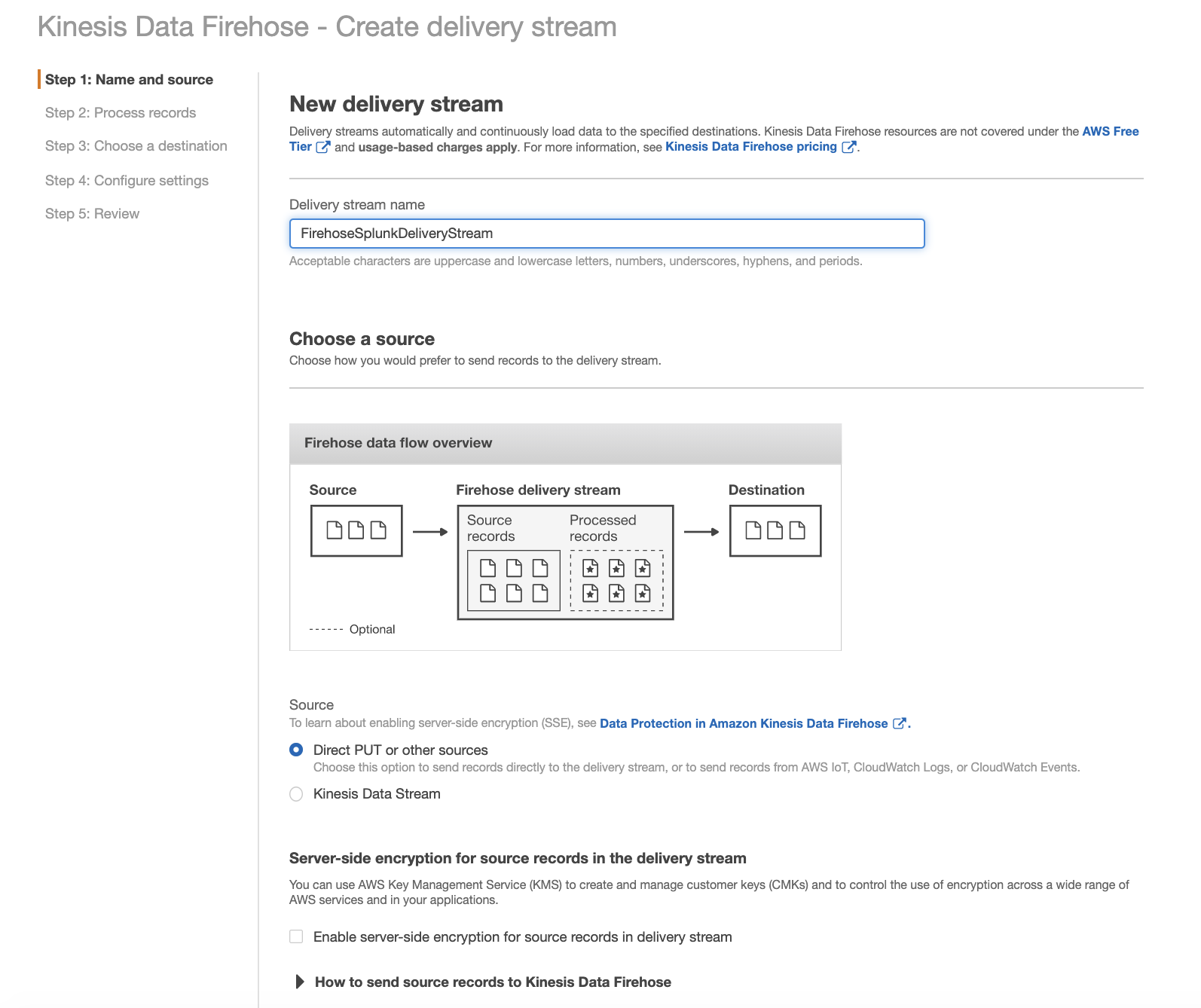
In the next section, you can specify whether you want to use an inline Lambda function for transformation. Because incoming CloudWatch Logs are gzip compressed, choose Enabled for Data transformation.
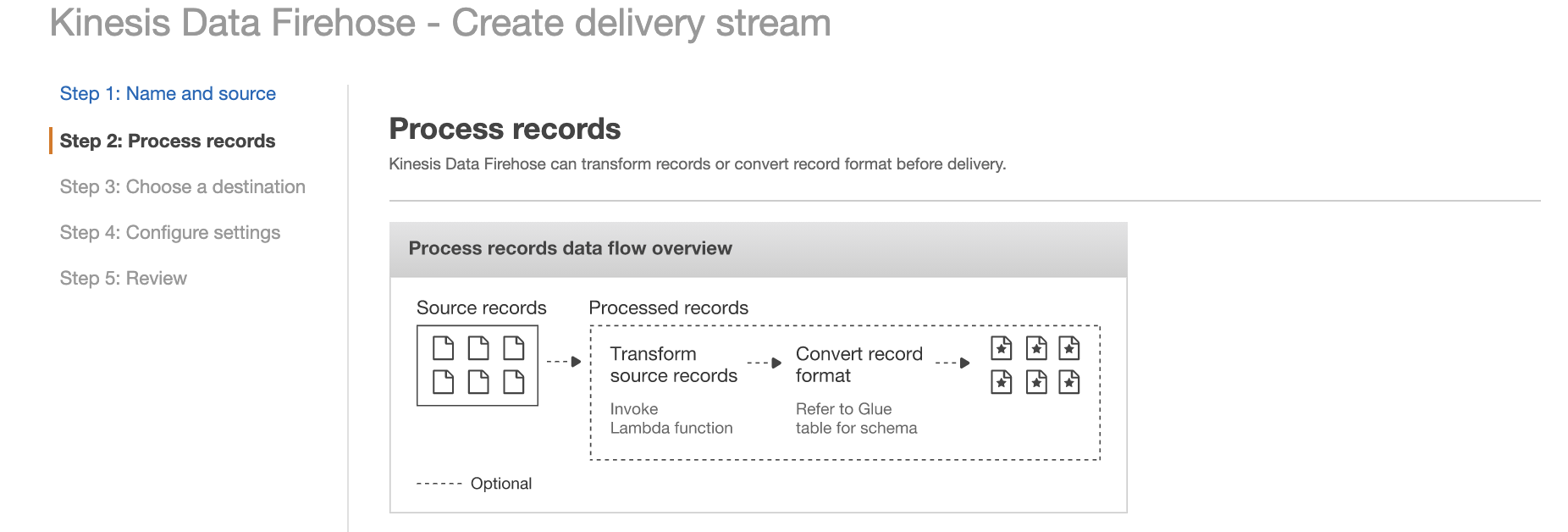
Choose Create new. From the list of the available blueprint functions, choose Kinesis Data Firehose CloudWatch Logs Processor. This function unzips data and place it back into the Firehose stream in compliance with the record transformation output model.
Enter a name for the Lambda function, choose Choose an existing role, and then choose the role you created earlier. Then choose Create Function.
Go back to the Firehose Stream wizard, choose the Lambda function you just created, and then choose Next.
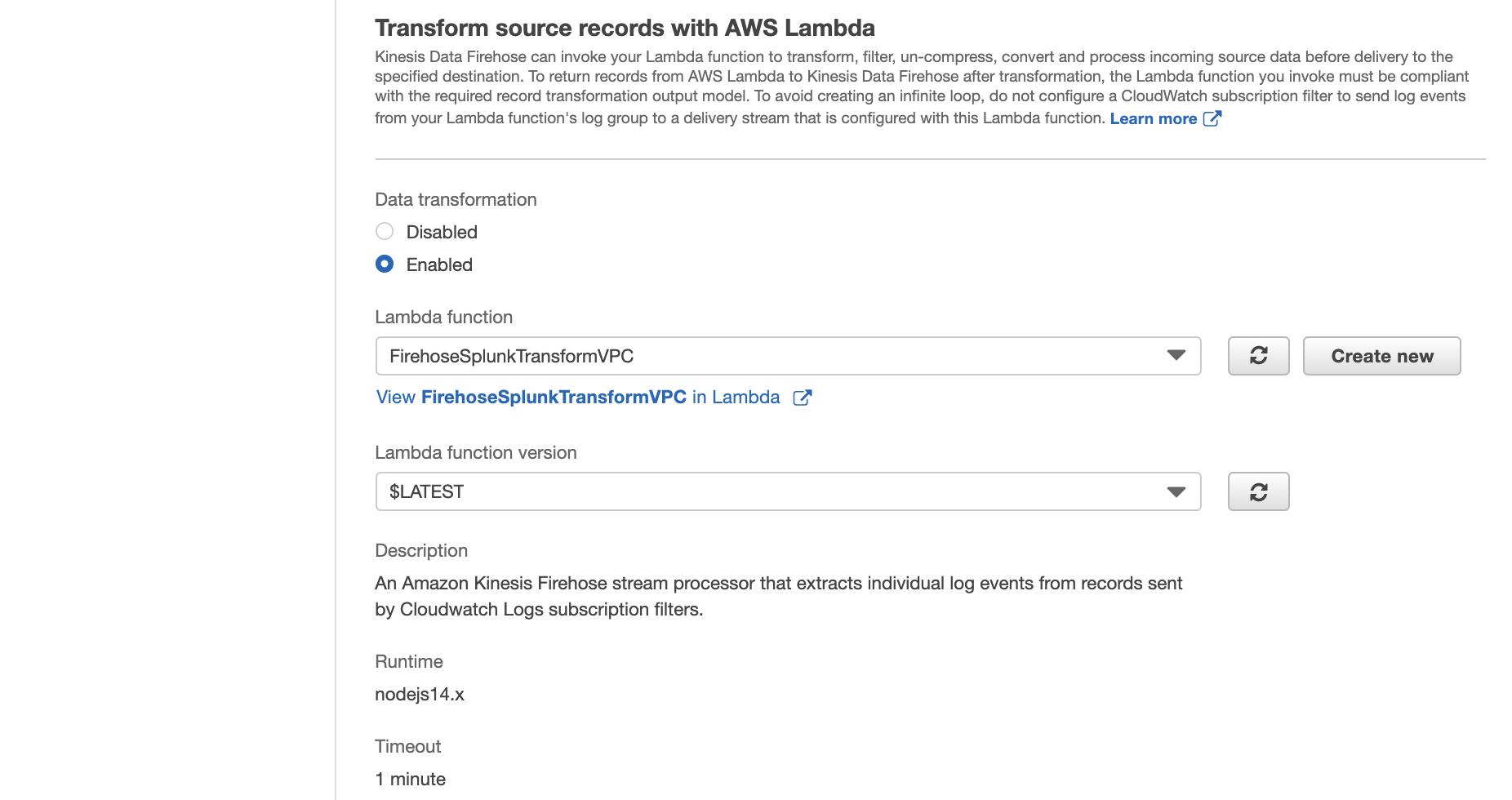
For this Lambda function code, refer to the appendix of this blog post.
Select HTTP Endpoint as the destination, and enter your Splunk HTTP Event Collector information.

Note: Amazon Kinesis Data Firehose requires the Splunk HTTP Event Collector (HEC) endpoint to be terminated with a valid CA-signed certificate matching the DNS hostname used to connect to your HEC endpoint. You receive delivery errors if you are using a self-signed certificate.
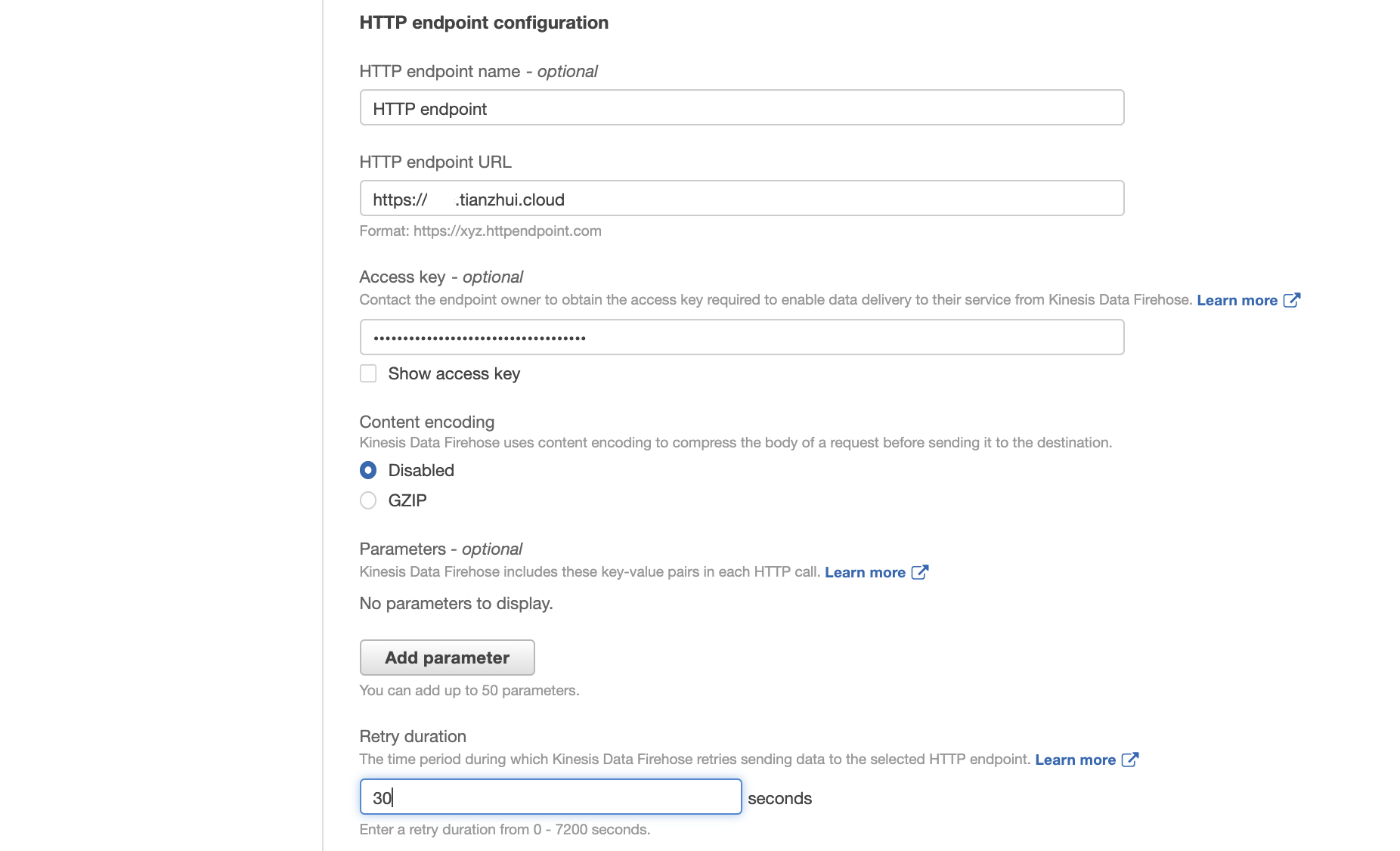
For HTTP endpoint URL, put the ALB's corresponding CNAME (e.g., example.tianzhui.cloud), which will be resolved to ALB's own DNS name in Route 53, and port number. The ALB should have HTTPS certificate associated with it, and its domain name should be exactly the same as ALB's CNAME.
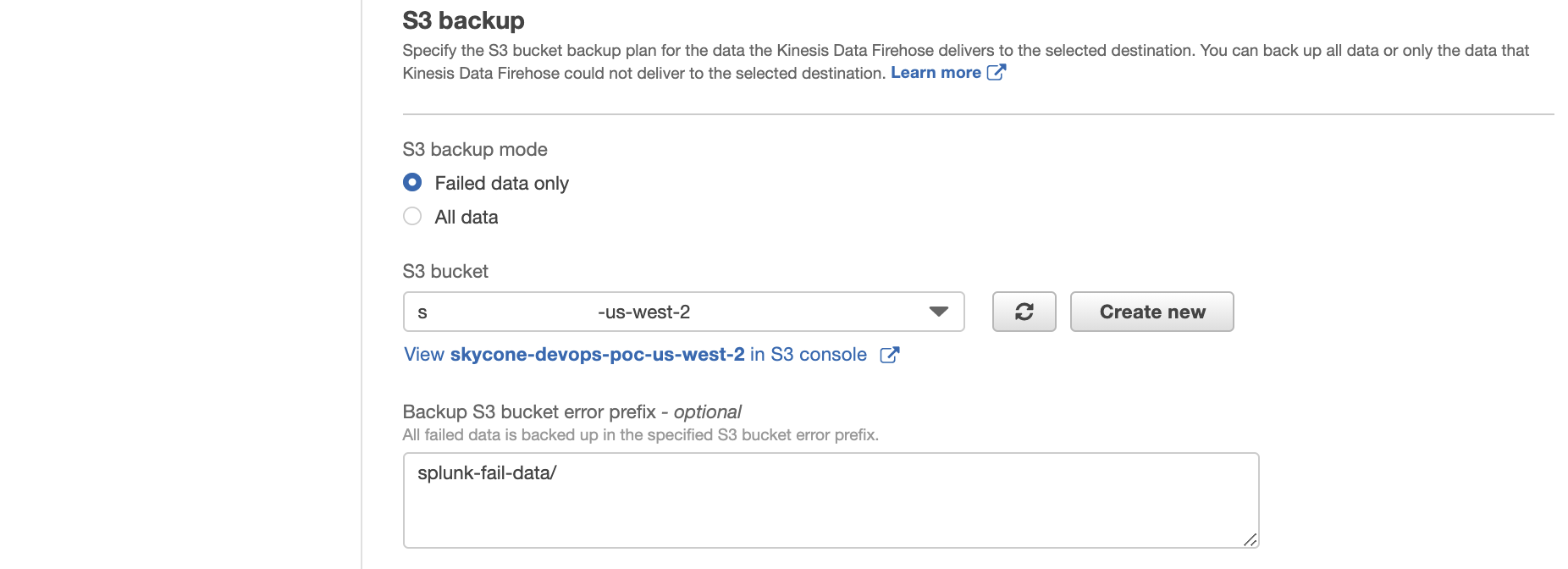
In this example, we only back up logs that fail during delivery. Pay attention that the prefix will not append a "/" automatically. If you want so, manually specify the "/".
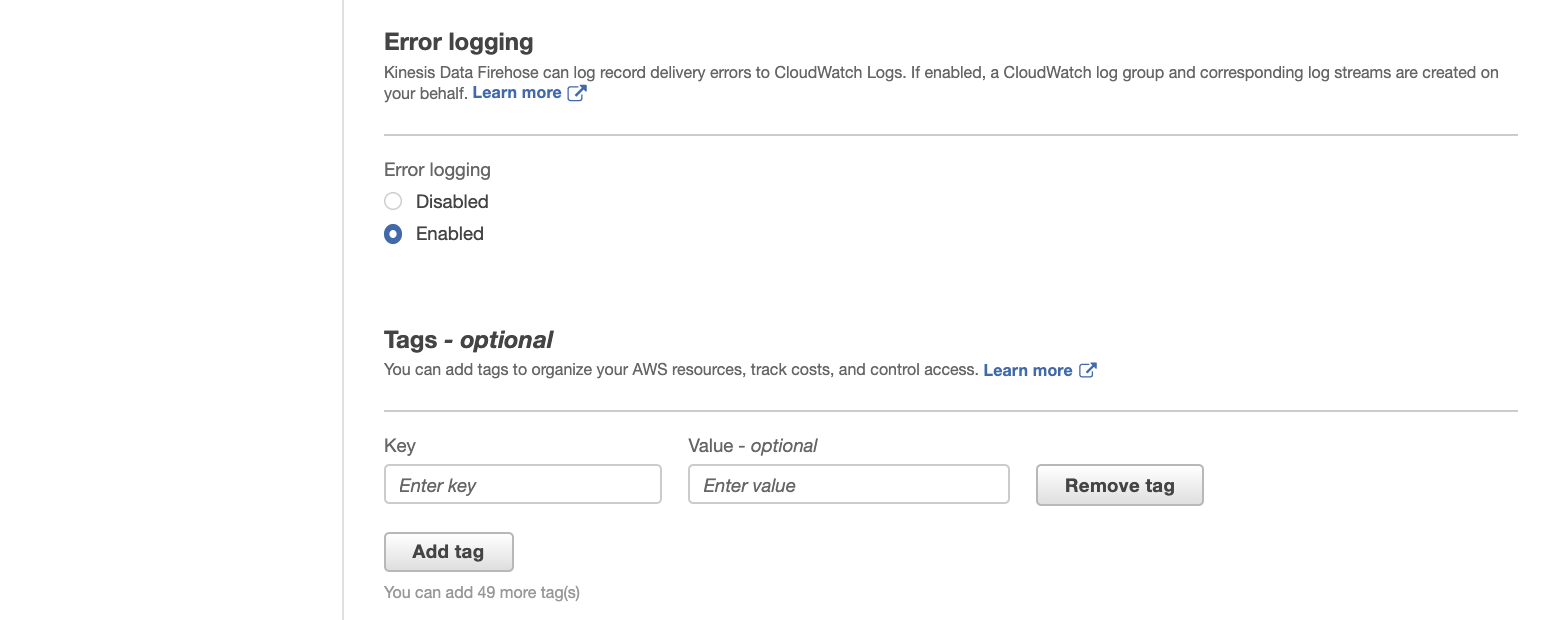
To monitor your Firehose delivery stream, enable error logging. Doing this means that you can monitor record delivery errors.
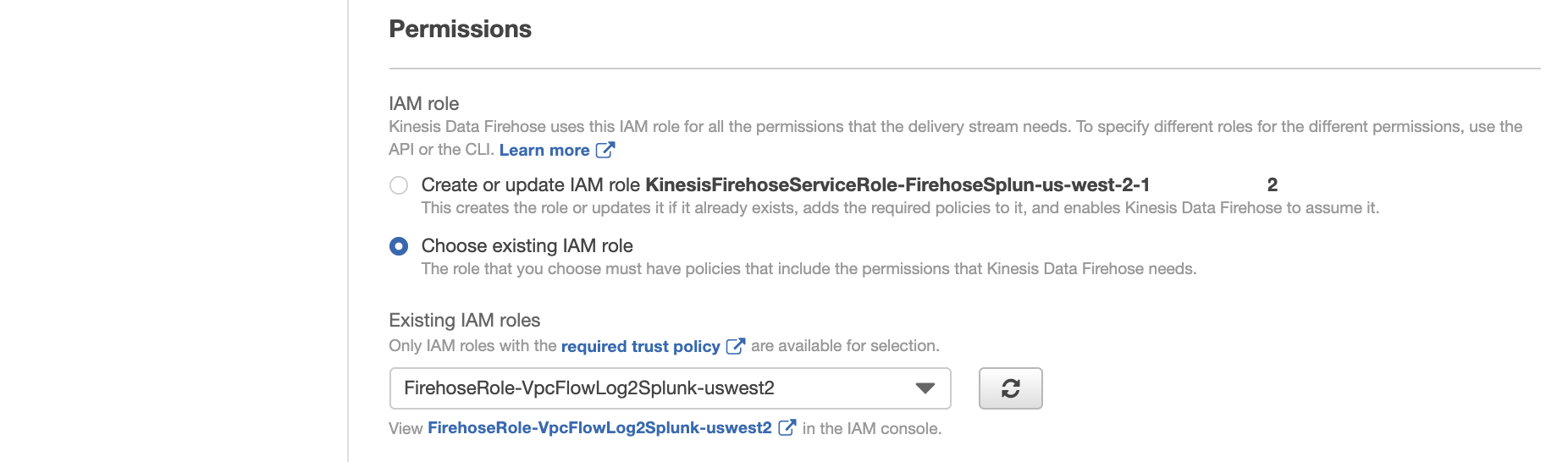
For IAM role, choose existing IAM role, i.e., FirehoseRoleVpcFlowLog.
You now get a chance to review and adjust the Firehose stream settings. When you are satisfied, choose Create Stream. You get a confirmation once the stream is created and active.
Create CloudWatch Log Group
Create CloudWatch log group, and specified its name as /vpc/flowlog/FirehoseSplunkDemo.
Create a VPC Flow Log
To send events from Amazon VPC, you need to set up a VPC flow log.
PS: If you already have a VPC flow log you want to use, you can skip to the “Publish CloudWatch to Kinesis Data Firehose” section.
On the AWS console, open the Amazon VPC service. Then choose VPC, Your VPC, and choose the VPC you want to send flow logs from. Choose Flow Logs, and then choose Create Flow Log.
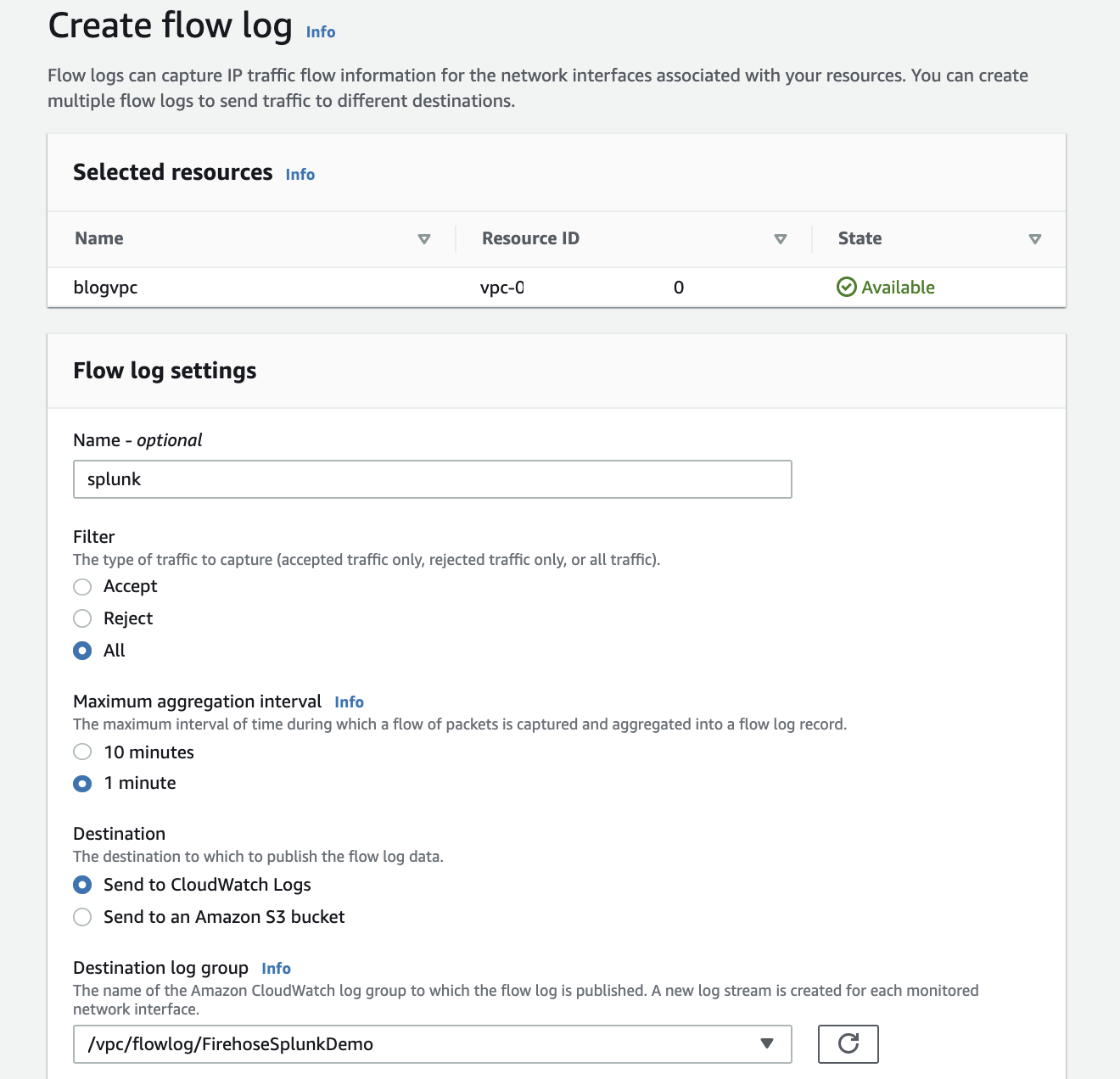
If you don’t have an IAM role that allows your VPC to publish logs to CloudWatch, choose Set Up Permissions and Create new role. Use the defaults when presented with the screen to create the new IAM role.
NB
Policy of IAM role "flow-logs".
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents",
"logs:DescribeLogGroups",
"logs:DescribeLogStreams"
],
"Effect": "Allow",
"Resource": "*"
}
]
}
Trust relationships{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "vpc-flow-logs.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
Once active, your VPC flow log should look like the following.
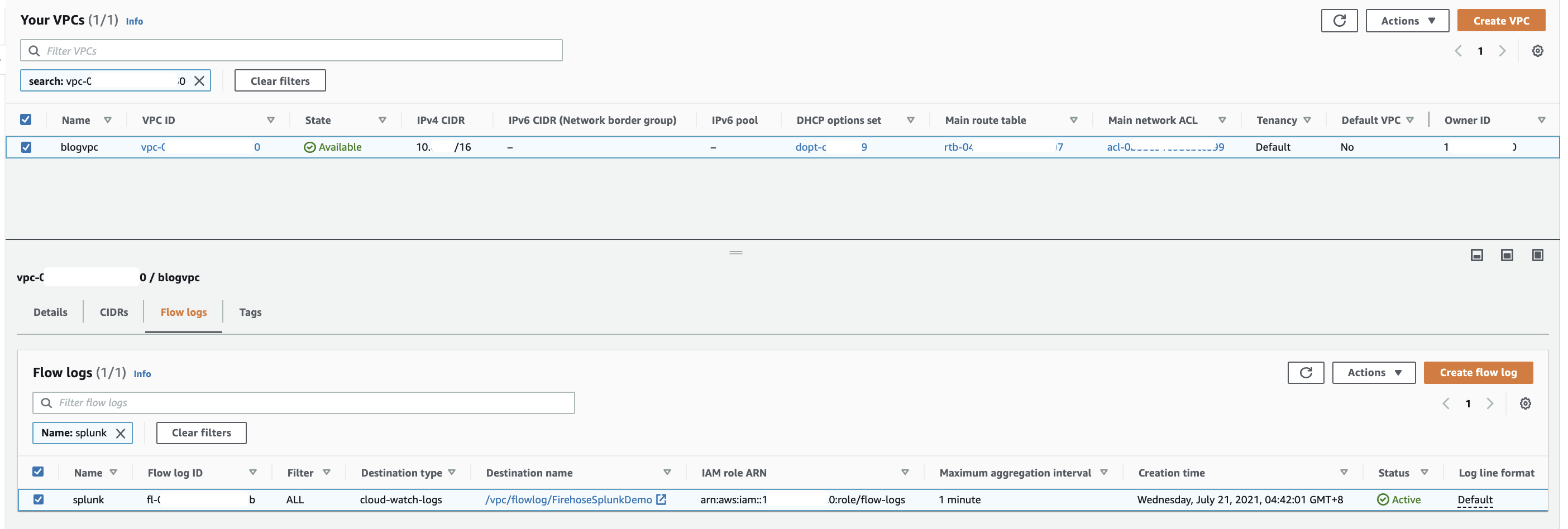
Publish CloudWatch to Kinesis Data Firehose
When you generate traffic to or from your VPC, the log group is created in Amazon CloudWatch. The new log group has no subscription filter, so set up a subscription filter. Setting this up establishes a real-time data feed from the log group to your Firehose delivery stream.
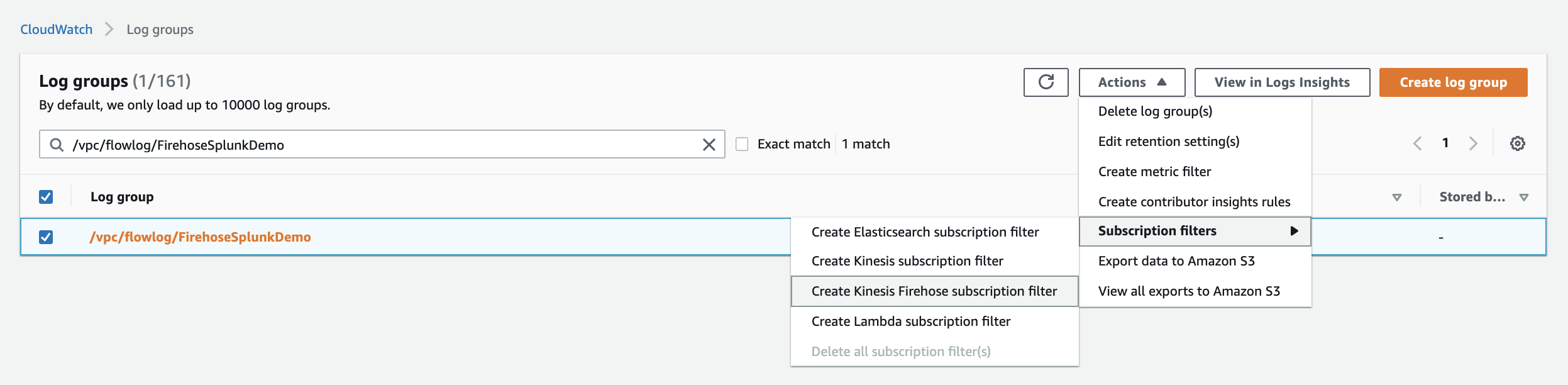
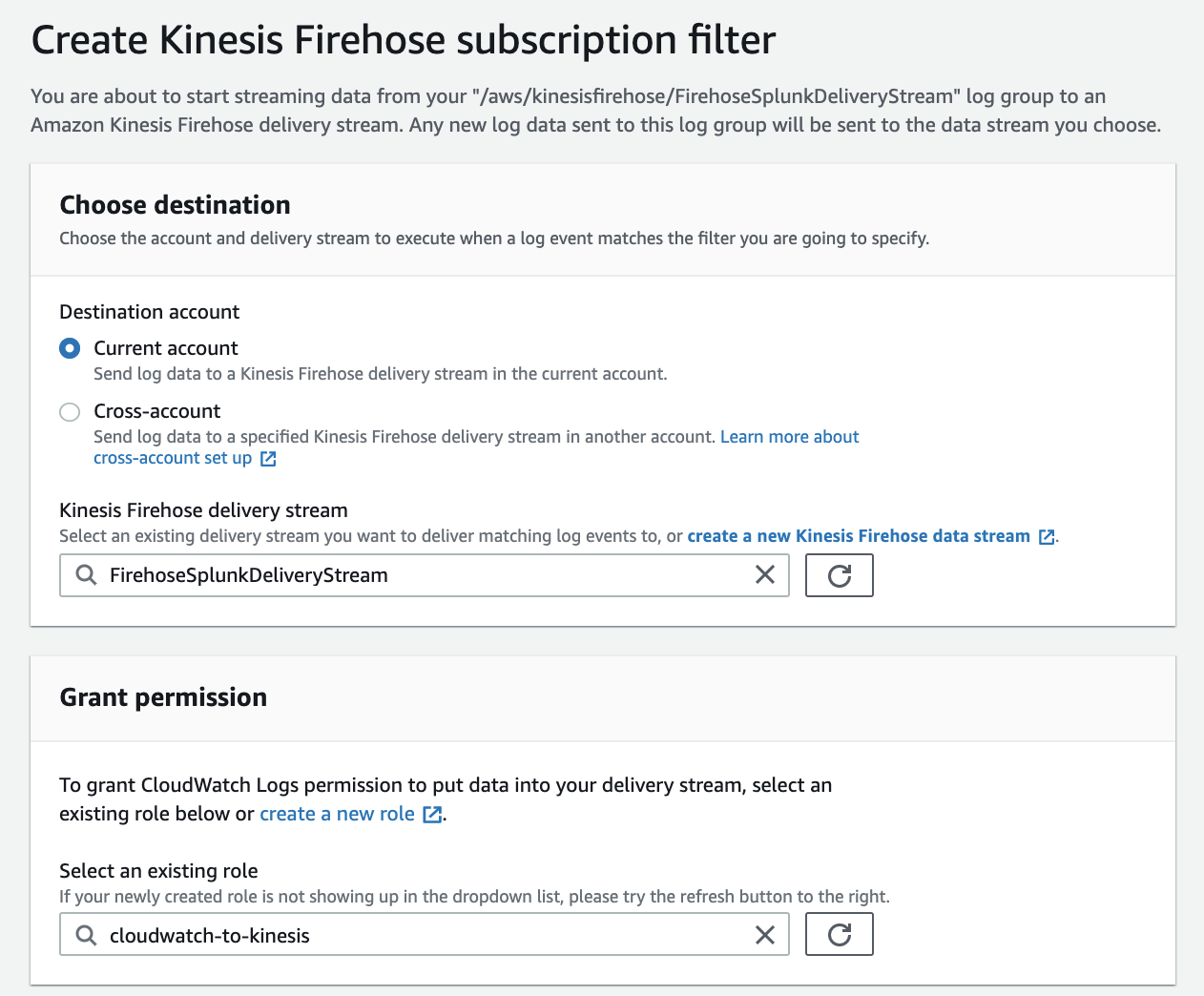
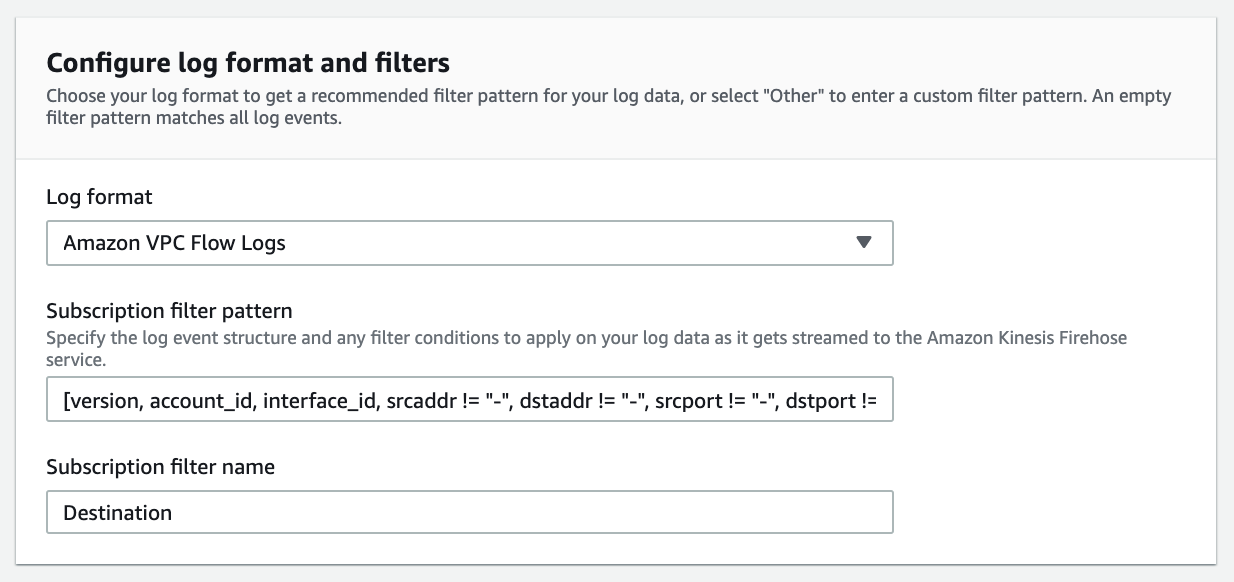
At present, you have to use the AWS Command Line Interface (AWS CLI) to create a CloudWatch Logs subscription to a Kinesis Data Firehose stream. However, you can use the AWS console to create subscriptions to Lambda and Amazon Elasticsearch Service.
To allow CloudWatch to publish to your Firehose stream, you need to give it permissions.
$ aws iam create-role --role-name CWLtoKinesisFirehoseRole --assume-role-policy-document file://TrustPolicyForCWLToFireHose.json
Here is the content for TrustPolicyForCWLToFireHose.json.
{
"Statement": {
"Effect": "Allow",
"Principal": {
"Service": "logs.us-west-2.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
}
Attach the policy to the newly created role.
$ aws iam put-role-policy
--role-name CWLtoKinesisFirehoseRole
--policy-name Permissions-Policy-For-CWL
--policy-document file://PermissionPolicyForCWLToFireHose.json
Content for PermissionPolicyForCWLToFireHose.json.
{
"Statement":[
{
"Effect":"Allow",
"Action": [
"firehose:PutRecord",
"firehose:PutRecordBatch"
],
"Resource":["arn:aws:firehose:us-west-2:YOUR-AWS-ACCT-NUM:deliverystream/FirehoseSplunkDeliveryStream"]
},
{
"Effect":"Allow",
"Action":["iam:PassRole"],
"Resource":["arn:aws:iam::YOUR-AWS-ACCT-NUM:role/CWLtoKinesisFirehoseRole"]
}
]
}
Finally, create a subscription filter.
$ aws logs put-subscription-filter
--log-group-name " /vpc/flowlog/FirehoseSplunkDemo"
--filter-name "Destination"
--filter-pattern ""
--destination-arn "arn:aws:firehose:us-east-1:YOUR-AWS-ACCT-NUM:deliverystream/FirehoseSplunkDeliveryStream"
--role-arn "arn:aws:iam::YOUR-AWS-ACCT-NUM:role/CWLtoKinesisFirehoseRole"
When you run the AWS CLI command preceding, you don’t get any acknowledgment. To validate that your CloudWatch Log Group is subscribed to your Firehose stream, check the CloudWatch console.
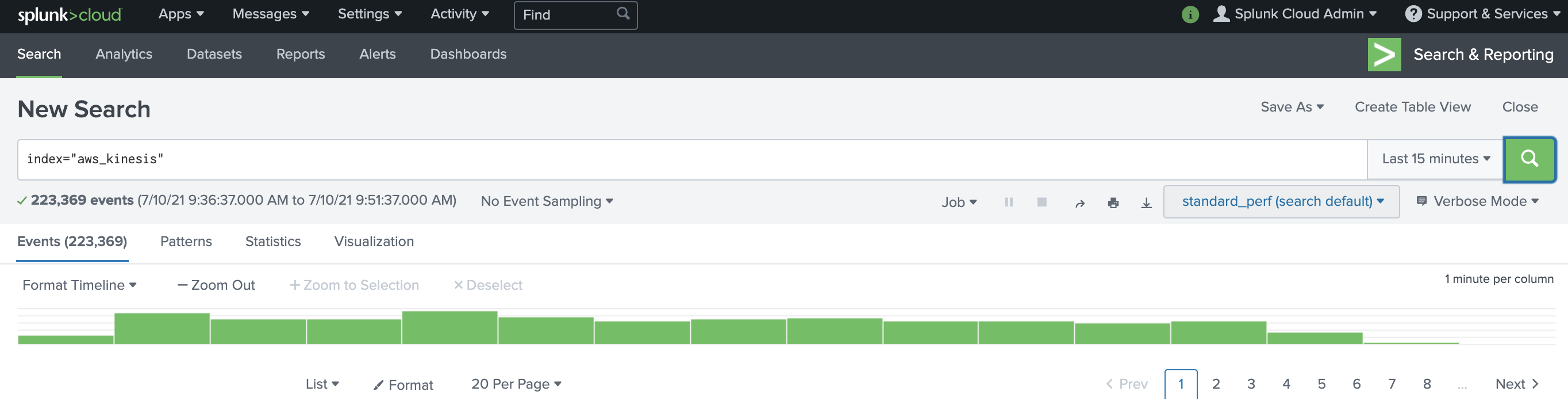
As soon as the subscription filter is created, the real-time log data from the log group goes into your Firehose delivery stream. Your stream then delivers it to your Splunk Enterprise or Splunk Cloud environment for querying and visualization. The screenshot following is from Splunk Enterprise.
In addition, you can monitor and view metrics associated with your delivery stream using the AWS console.
Appendix
Lambda function code, i.e., FirehoseSplunkTransformVPC
// Copyright 2014, Amazon.com, Inc. or its affiliates. All Rights Reserved.
//
// Licensed under the Amazon Software License (the "License").
// You may not use this file except in compliance with the License.
// A copy of the License is located at
//
// http://aws.amazon.com/asl/
//
// or in the "license" file accompanying this file. This file is distributed
// on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either
// express or implied. See the License for the specific language governing
// permissions and limitations under the License.
/*
For processing data sent to Firehose by Cloudwatch Logs subscription filters.
Cloudwatch Logs sends to Firehose records that look like this:
{
"messageType": "DATA_MESSAGE",
"owner": "123456789012",
"logGroup": "log_group_name",
"logStream": "log_stream_name",
"subscriptionFilters": [
"subscription_filter_name"
],
"logEvents": [
{
"id": "01234567890123456789012345678901234567890123456789012345",
"timestamp": 1510109208016,
"message": "log message 1"
},
{
"id": "01234567890123456789012345678901234567890123456789012345",
"timestamp": 1510109208017,
"message": "log message 2"
}
...
]
}
The data is additionally compressed with GZIP.
NOTE: It is suggested to test the cloudwatch logs processor lambda function in a pre-production environment to ensure
the 6000000 limit meets your requirements. If your data contains a sizable number of records that are classified as
Dropped/ProcessingFailed, then it is suggested to lower the 6000000 limit within the function to a smaller value
(eg: 5000000) in order to confine to the 6MB (6291456 bytes) payload limit imposed by lambda. You can find Lambda
quotas at https://docs.aws.amazon.com/lambda/latest/dg/gettingstarted-limits.html
The code below will:
1) Gunzip the data
2) Parse the json
3) Set the result to ProcessingFailed for any record whose messageType is not DATA_MESSAGE, thus redirecting them to the
processing error output. Such records do not contain any log events. You can modify the code to set the result to
Dropped instead to get rid of these records completely.
4) For records whose messageType is DATA_MESSAGE, extract the individual log events from the logEvents field, and pass
each one to the transformLogEvent method. You can modify the transformLogEvent method to perform custom
transformations on the log events.
5) Concatenate the result from (4) together and set the result as the data of the record returned to Firehose. Note that
this step will not add any delimiters. Delimiters should be appended by the logic within the transformLogEvent
method.
6) Any individual record exceeding 6,000,000 bytes in size after decompression and encoding is marked as
ProcessingFailed within the function. The original compressed record will be backed up to the S3 bucket
configured on the Firehose.
7) Any additional records which exceed 6MB will be re-ingested back into Firehose.
8) The retry count for intermittent failures during re-ingestion is set 20 attempts. If you wish to retry fewer number
of times for intermittent failures you can lower this value.
*/
const zlib = require('zlib');
const AWS = require('aws-sdk');
/**
* logEvent has this format:
*
* {
* "id": "01234567890123456789012345678901234567890123456789012345",
* "timestamp": 1510109208016,
* "message": "log message 1"
* }
*
* The default implementation below just extracts the message and appends a newline to it.
*
* The result must be returned in a Promise.
*/
function transformLogEvent(logEvent) {
return Promise.resolve(`${logEvent.message}\n`);
}
function putRecordsToFirehoseStream(streamName, records, client, resolve, reject, attemptsMade, maxAttempts) {
client.putRecordBatch({
DeliveryStreamName: streamName,
Records: records,
}, (err, data) => {
const codes = [];
let failed = [];
let errMsg = err;
if (err) {
failed = records;
} else {
for (let i = 0; i < data.RequestResponses.length; i++) {
const code = data.RequestResponses[i].ErrorCode;
if (code) {
codes.push(code);
failed.push(records[i]);
}
}
errMsg = `Individual error codes: ${codes}`;
}
if (failed.length > 0) {
if (attemptsMade + 1 < maxAttempts) {
console.log('Some records failed while calling PutRecordBatch, retrying. %s', errMsg);
putRecordsToFirehoseStream(streamName, failed, client, resolve, reject, attemptsMade + 1, maxAttempts);
} else {
reject(`Could not put records after ${maxAttempts} attempts. ${errMsg}`);
}
} else {
resolve('');
}
});
}
function putRecordsToKinesisStream(streamName, records, client, resolve, reject, attemptsMade, maxAttempts) {
client.putRecords({
StreamName: streamName,
Records: records,
}, (err, data) => {
const codes = [];
let failed = [];
let errMsg = err;
if (err) {
failed = records;
} else {
for (let i = 0; i < data.Records.length; i++) {
const code = data.Records[i].ErrorCode;
if (code) {
codes.push(code);
failed.push(records[i]);
}
}
errMsg = `Individual error codes: ${codes}`;
}
if (failed.length > 0) {
if (attemptsMade + 1 < maxAttempts) {
console.log('Some records failed while calling PutRecords, retrying. %s', errMsg);
putRecordsToKinesisStream(streamName, failed, client, resolve, reject, attemptsMade + 1, maxAttempts);
} else {
reject(`Could not put records after ${maxAttempts} attempts. ${errMsg}`);
}
} else {
resolve('');
}
});
}
function createReingestionRecord(isSas, originalRecord) {
if (isSas) {
return {
Data: Buffer.from(originalRecord.data, 'base64'),
PartitionKey: originalRecord.kinesisRecordMetadata.partitionKey,
};
} else {
return {
Data: Buffer.from(originalRecord.data, 'base64'),
};
}
}
function getReingestionRecord(isSas, reIngestionRecord) {
if (isSas) {
return {
Data: reIngestionRecord.Data,
PartitionKey: reIngestionRecord.PartitionKey,
};
} else {
return {
Data: reIngestionRecord.Data,
};
}
}
exports.handler = (event, context, callback) => {
Promise.all(event.records.map(r => {
const buffer = Buffer.from(r.data, 'base64');
let decompressed;
try {
decompressed = zlib.gunzipSync(buffer);
} catch (e) {
return Promise.resolve({
recordId: r.recordId,
result: 'ProcessingFailed',
});
}
const data = JSON.parse(decompressed);
// CONTROL_MESSAGE are sent by CWL to check if the subscription is reachable.
// They do not contain actual data.
if (data.messageType === 'CONTROL_MESSAGE') {
return Promise.resolve({
recordId: r.recordId,
result: 'Dropped',
});
} else if (data.messageType === 'DATA_MESSAGE') {
const promises = data.logEvents.map(transformLogEvent);
return Promise.all(promises)
.then(transformed => {
const payload = transformed.reduce((a, v) => a + v, '');
const encoded = Buffer.from(payload).toString('base64');
if (encoded.length <= 6000000) {
return {
recordId: r.recordId,
result: 'Ok',
data: encoded,
};
} else {
return {
recordId: r.recordId,
result: 'ProcessingFailed',
};
}
});
} else {
return Promise.resolve({
recordId: r.recordId,
result: 'ProcessingFailed',
});
}
})).then(recs => {
const isSas = Object.prototype.hasOwnProperty.call(event, 'sourceKinesisStreamArn');
const streamARN = isSas ? event.sourceKinesisStreamArn : event.deliveryStreamArn;
const region = streamARN.split(':')[3];
const streamName = streamARN.split('/')[1];
const result = { records: recs };
let recordsToReingest = [];
const putRecordBatches = [];
let totalRecordsToBeReingested = 0;
const inputDataByRecId = {};
event.records.forEach(r => inputDataByRecId[r.recordId] = createReingestionRecord(isSas, r));
let projectedSize = recs.filter(rec => rec.result === 'Ok')
.map(r => r.recordId.length + r.data.length)
.reduce((a, b) => a + b, 0);
// 6000000 instead of 6291456 to leave ample headroom for the stuff we didn't account for
for (let idx = 0; idx < event.records.length && projectedSize > 6000000; idx++) {
const rec = result.records[idx];
if (rec.result === 'Ok') {
totalRecordsToBeReingested++;
recordsToReingest.push(getReingestionRecord(isSas, inputDataByRecId[rec.recordId]));
projectedSize -= rec.data.length;
delete rec.data;
result.records[idx].result = 'Dropped';
// split out the record batches into multiple groups, 500 records at max per group
if (recordsToReingest.length === 500) {
putRecordBatches.push(recordsToReingest);
recordsToReingest = [];
}
}
}
if (recordsToReingest.length > 0) {
// add the last batch
putRecordBatches.push(recordsToReingest);
}
if (putRecordBatches.length > 0) {
new Promise((resolve, reject) => {
let recordsReingestedSoFar = 0;
for (let idx = 0; idx < putRecordBatches.length; idx++) {
const recordBatch = putRecordBatches[idx];
if (isSas) {
const client = new AWS.Kinesis({ region: region });
putRecordsToKinesisStream(streamName, recordBatch, client, resolve, reject, 0, 20);
} else {
const client = new AWS.Firehose({ region: region });
putRecordsToFirehoseStream(streamName, recordBatch, client, resolve, reject, 0, 20);
}
recordsReingestedSoFar += recordBatch.length;
console.log('Reingested %s/%s records out of %s in to %s stream', recordsReingestedSoFar, totalRecordsToBeReingested, event.records.length, streamName);
}
}).then(
() => {
console.log('Reingested all %s records out of %s in to %s stream', totalRecordsToBeReingested, event.records.length, streamName);
callback(null, result);
},
failed => {
console.log('Failed to reingest records. %s', failed);
callback(failed, null);
});
} else {
console.log('No records needed to be reingested.');
callback(null, result);
}
}).catch(ex => {
console.log('Error: ', ex);
callback(ex, null);
});
};
Error code:
The response received from the endpoint is invalid. See Troubleshooting HTTP Endpoints in the Firehose documentation for more information. Reason:. Response for request 4b16354e-7e52-4d4d-aab8-78fa051f95a1 must contain a 'content-type: application/json' header. Raw response received: 303: <!doctype html><html><head><meta http-equiv="content-type" content="text/html; charset=UTF-8"><meta http-equiv="refresh" content="1;url=https://prd-p-6szuw.splunkcloud.com/en-US/"><title>303 See Other</title></head><body><h1>See Other</h1><p>The resource has moved temporarily <a href="https://prd-p-6szuw.splunkcloud.com/en-US/">here</a>.</p></body></html>
Error message #2:
The data could not be decoded as UTF-8Error code: InvalidEncodingException
Source="kinesis://FirehoseSplunkDeliveryStreamOutputSplunk"
The HTTP Event Collector receives data over HTTPS on TCP port 8088 by default. You can change the port as well as disable HTTPS by clicking on the Global Settings button at the top of the HTTP Event Collector management page.
References
Power data ingestion into Splunk using Amazon Kinesis Data Firehose
Troubleshooting HTTP Endpoints
Quickstart (Python requests module)
Configure Amazon Kinesis Firehose to send data to the Splunk platform
Announcing new AWS Lambda Blueprints for Splunk
Kinesis Firehose - InvalidEncodingException - Cant get Cloudwatch logs in
Integrating Splunk with Amazon Kinesis Streams
Set up and use HTTP Event Collector in Splunk Web
Install and configure the Splunk Add-on for Amazon Kinesis Firehose on a paid Splunk Cloud deployment
Installation steps for the Splunk Add-on for Amazon Kinesis Firehose on a Paid Splunk Cloud deployment
Installation and configuration overview for the Splunk Add-on for Amazon Kinesis Firehose
Configure Amazon Kinesis Firehose to send data to the Splunk platform
What you need for this tutorial
Splunk Cloud deployment types
HTTP Event Collector examples
Set up and use HTTP Event Collector in Splunk Web
Hardware and software requirements for the Splunk Add-on for Amazon Kinesis Firehose
How come my AWS Kinesis Firehose is failing to connect to HEC due to SSL Handshake?
AWS Kenisis Data Stream Fails with "Could not connect to the HEC endpoint. Make sure that the certificate and the host are valid"
Why am I getting error "Data channel is missing" using HTTP Event Collector with Splunk Light?
-