Welcome to my blog. The topics here include: public clouds (AWS, Alibaba Cloud, Azure, Tencent Cloud
and Google Cloud), big data, Serverless, DevOps, and IaC.
Any question try to contact me: leo@tianzhui.cloud.
Task: Predict if someone is looking for a job. (x = user data, y = looking for a job?) Keep track of data provenance (where it comes from) and lineage (sequence of steps)
Meta-data
Examples:
Manufacturing visual inspection: Time, factory, line #, camera settings, phone model, inspector ID, ...
Speech recognition: Device type, labeler ID, VAD model ID
Useful for:
Error analysis. Spotting unexpected effects.
Keeping track of data provenance.
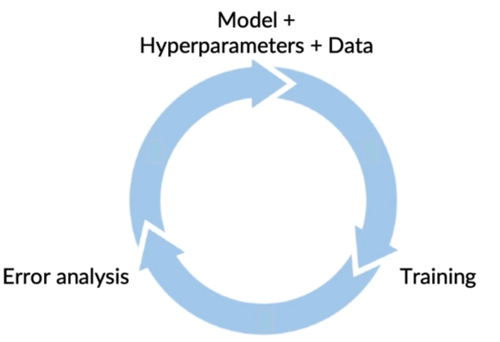
4. Balanced train/dev/test splits
Balanced train/dev/test splits in small data problems
No need to worry about this with large datasets - a random split will be representative.
5. [IMPORTANT] Reminder about end of access to Lab Notebooks
6. Data Stage of the ML Production Lifecycle
Question 1 Which of these statements is correct regarding structured vs. unstructured data problems?
It is generally easier for humans to label data for structured data, and easier to apply data augmentation for unstructured data.
It is generally easier for humans to label data and to apply data augmentation for structured data than unstructured data.
It is generally easier for humans to label data for unstructured data, and easier to apply data augmentation for structured data.
It is generally easier for humans to label data and to apply data augmentation for unstructured data than structured data.
Question 2 Take speech recognition. Some labelers transcribe with “...” (as in, “Um… today’s weather”) whereas others do so with commas “,”. Human-level performance (HLP) is measured according to how well one transcriber agrees with another. You work with the team and get everyone to consistently use commas “,”. What effect will this have on HLP?
HLP will stay the same.
HLP will increase.
HLP will decrease.
Question 3 Take a phone visual inspection problem. Suppose even a human inspector looking at an image cannot tell if there is a scratch. If however the same inspector were to look at the phone directly (rather than an image of the phone) then they can clearly tell if there is a scratch. Your goal is to build a system that gives accurate inspection decisions for the factory (not publish a paper). What would you do?
Get a big dataset of many training examples, since this is a challenging problem that will require a big dataset to do well on.
Try to improve the consistency of the labels, y.
Try to improve their imaging (camera/lighting) system to improve the quality or clarity of the input images, x.
Carefully measure HLP on this problem (which will be low) to make sure the algorithm can match HLP.
Question 4 You are building a system to detect cats. You ask labelers to please “use bounding boxes to indicate the position of cats.” Different labelers label as follows:
What is the most likely cause of this?
That this should have been posed as a segmentation rather than a detection task.
Lazy labelers.
Ambiguous labeling instructions.
Labelers have not had enough coffee.
Question 5 You are building a visual inspection system. HLP is measured according to how well one inspector agrees with another. Error analysis finds:
Type of defect
Accuracy
HLP
% of data
Scratch
95%
98%
50%
Discoloration
90%
90%
50%
You decide that it might be worth checking for label consistency on both scratch and discoloration defects. If you had to pick one to start with, which would you pick?
It is more promising to check (and potentially improve) label consistency on scratch defects than discoloration defects, since HLP is higher on scratch defects and thus it’s more reasonable to expect high consistency.
It is more promising to check (and potentially improve) label consistency on discoloration defects than scratch defects. Since HLP is lower on discoloration, it's possible that there might be ambiguous labelling instructions that are affecting HLP.
Question 6 To implement the data iteration loop effectively, the key is to take all the time that’s needed to construct the right dataset first, so that all development can be done on that dataset without needing to spend time to update the data.
True
False
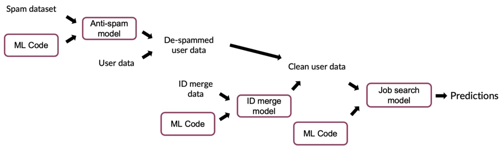
Question 7 You have a data pipeline for product recommendations that (i) cleans data by removing duplicate entries and spam, (ii) makes predictions. An engineering team improves the system used for step (i). If the trained model for step (ii) remains the same, what can we confidently conclude about the performance of the overall system?
It will get worse because changing an earlier stage in a data pipeline always results in worse performance of the later stages.
It will get worse because stage (ii) is now experiencing data/concept drift.
It's not possible to say - it may perform better or worse.
It will definitely improve since the data is now more clean.
Question 8 What is the primary goal of building a PoC (proof of concept) system?
To build a robust deployment system.
To check feasibility and help decide if an application is workable and worth deploying.
To collect sufficient data to build a robusts system for deployment.
To select the most appropriate ML architecture for a task.
Question 9 MLOps tools can store meta-data to keep track of data provenance and lineage. What do the terms data provenance and lineage mean?
Data provenance refers to the sequence of processing steps applied to a dataset, and data lineage refers to where the data comes from.
Data provenance refers the input x, and data lineage refers to the output y.
Data provenance refers data pipeline, and data lineage refers to the age of the data (i.e., how recently was it collected).
Data provenance refers to where the data comes from, and data lineage the sequence of processing steps applied to it.
Question 10 You are working on phone visual inspection, where the task is to use an input image, x, to classify defects, y. You have stored meta-data for your entire ML system, such as which factory each image came from. Which of the following are reasonable uses of meta-data?
As another input provided to human labelers (in addition to the image x) to boost HLP.
To suggest tags or to generate insights during error analysis.