Implementing Real-Time Data Replication from Core Database to Other Datastores: A Comprehensive Guide
This blog post explains how to replicate data from a RDMBS database, such as Aurora MySQL, to other data stores.
I will use my web-site's solution for illustration. Its core database sits in the central of the architecture and holds the master data. There are also other types of data services inside my site.
The reason to leverage different types of data services is due to the requirements of different micro-services and to leverage the inherent nature of each data service. For example, Aurora is a RDMBS and is more suitable for transcational tasks. Elasticsearch by its nature is a search and analytics engine, and is more suitable for full-text search scenarios. DynamoDB is a fast NoSQL key-value data store, and is used for storing the metadata in my case.
Hello, this is Leo, a cloud specialist and evangelist focusing on various cutting-edge solutions and mainstream public cloud technologies. In this blog post, I will explain a solution to capture data changes on the core database, and to replicate them to other data stores, in real-time.
This post is an update of a previous blog post. I wrote this post after my Aurora MySQL upgraded from version 2 to version 3. The trigger to write this dedicated post and to share the experience is that, in version 3, stored procedure is not available, and need to be replaced by native function. Although the previous post is a little bit out-dated, I would expect you can still get valuable information from that post by quickly read through it, because the very beginning background and some design considerations were covered in that post and not duplicated in this one.
The overall architecture looks like the following diagram.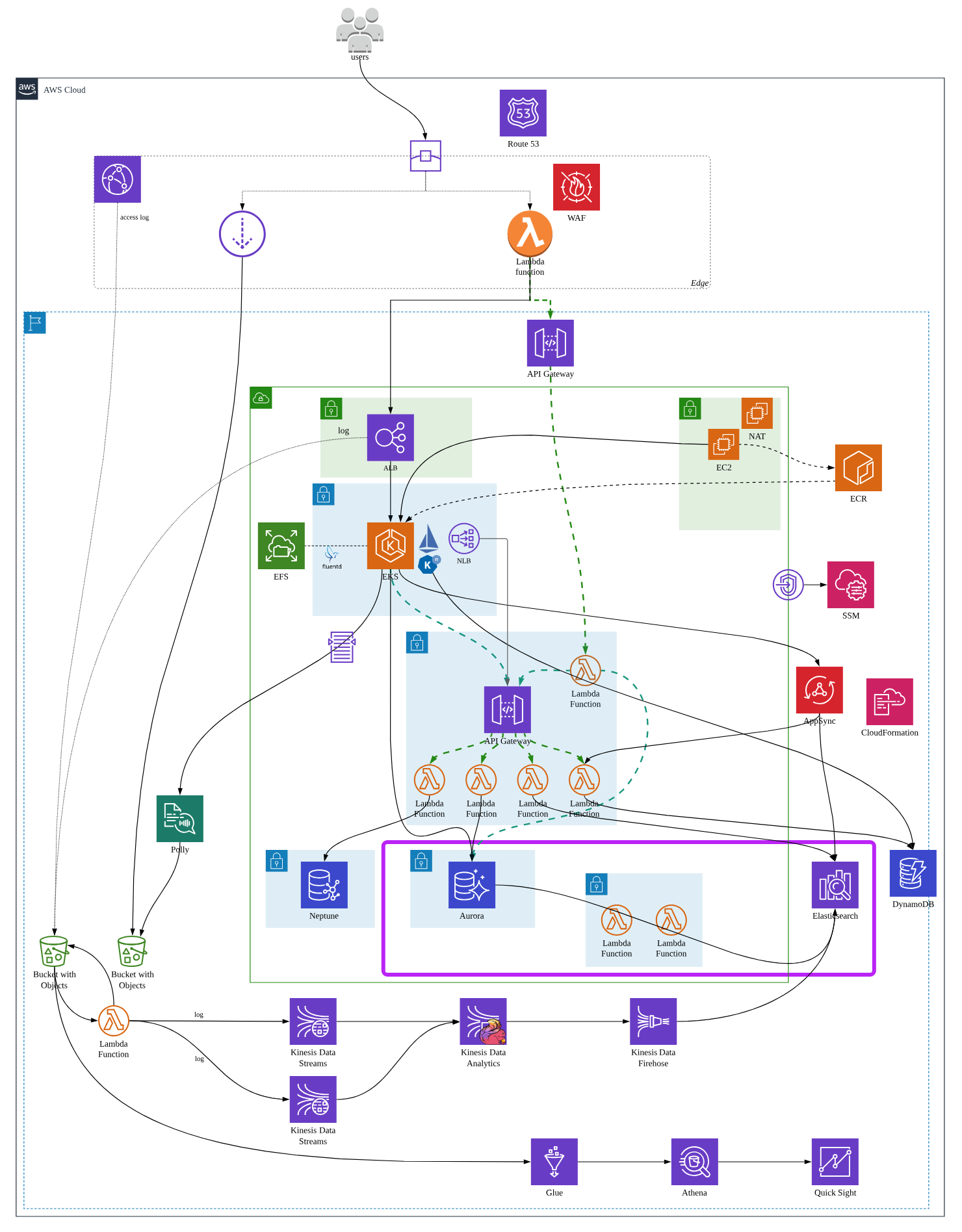
This blog post focus on the circled part in the above diagram.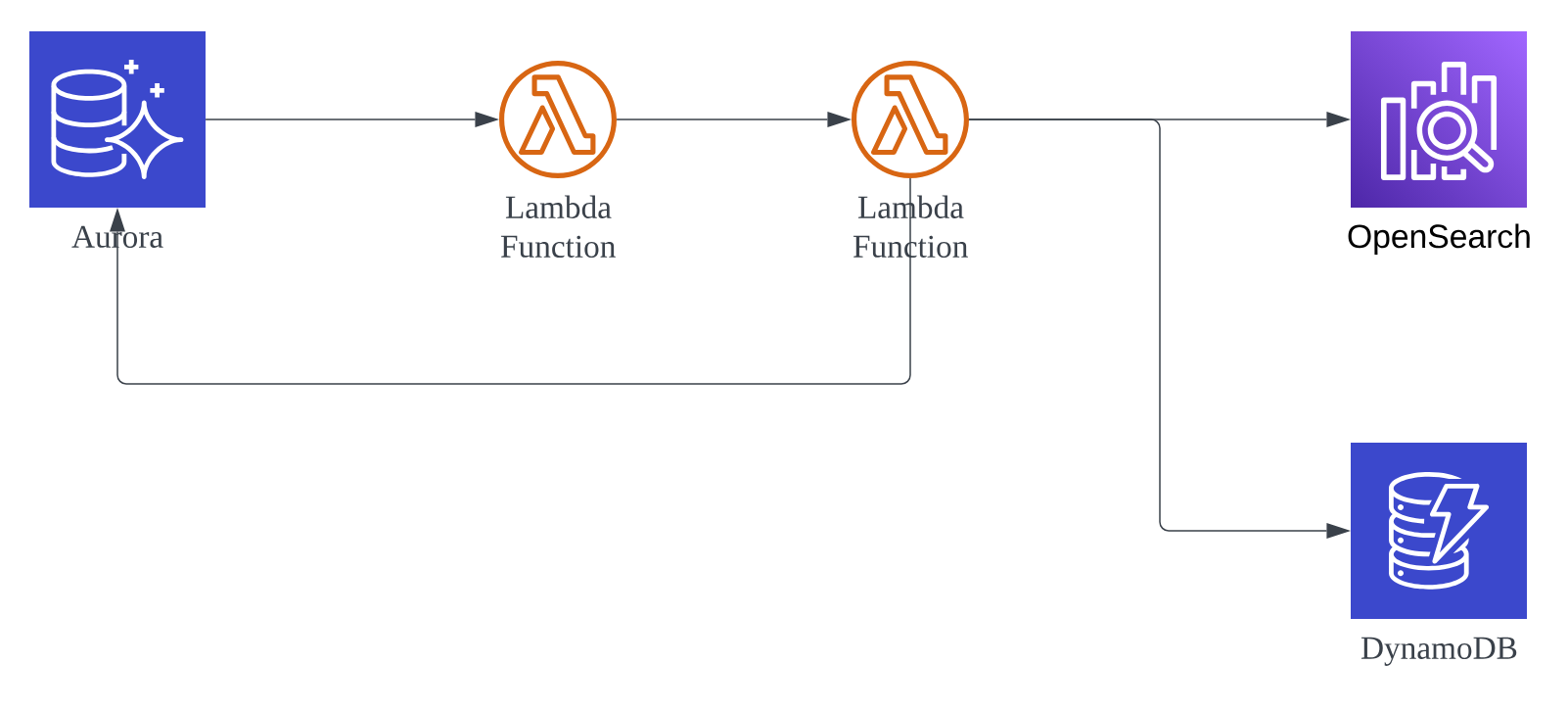
In this case, CDC (Change Data Capture) is used to capture the data change happened on Aurora MySQL, which serves as the core database of the entire architecture. Aurora MySQL native function will be used to perform this action.
Note
Stored procedure becomes unavailable since Aurora MySQL version 3. You will encounter the following error log if you upgrade Aurora MySQL version 2 to version 3, AND, if the previous Aurora MySQL version 2 has stored procedure in it.
... ERROR 2023-07-14 11:14:48,196 views 15 140477946771264 (1305, 'PROCEDURE mysql.lambda_async does not exist') ...
Data will firstly land in the core database. After that, an async call will be triggered to invoke a Lambda function. That Lambda function is responsible to parse the event and then call the next Lambda function. The second Lambda function will use the received primary key to read the row in question from the database, and feed that data to OpenSearch and other data services.
From business perspective, the first Lambda function is to figure out the post in question has taken place which type of action, and what is the corresponding primary key. It is really cost inefficient to carry all of the row data over the async call, because, the content of a post could be very large, and the first Lambda function ONLY need a few selective columns, including action type (UPDATE and DELETE) and the primary key, to take action. Therefore, only these fields will be fed into this Lambda function.
Note
In this case, the native function will only respond to actions including UPDATE and DELETE. INSERT is not of its concern.
Create an IAM role with below settings
IAM role policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "lambda:InvokeFunction",
"Resource": "arn:aws:lambda:us-west-2:111122223333:function:<Lambda function name>"
}
]
}
Trust relationship:{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "rds.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
Invoking a Lambda function with an Aurora MySQL native function
You can call the native functions lambda_sync and lambda_async when you use Aurora MySQL version 2, or Aurora MySQL version 3.01 and higher.
You can invoke an AWS Lambda function from an Aurora MySQL DB cluster by calling the native functions lambda_sync and lambda_async. This approach can be useful when you want to integrate your database running on Aurora MySQL with other AWS services. For example, you might want to send a notification using Amazon SNS whenever a row is inserted into a specific table in your database.
Working with native functions to invoke a Lambda function
The lambda_sync and lambda_async functions are built-in, native functions that invoke a Lambda function synchronously or asynchronously. When you must know the result of the Lambda function before moving on to another action, use the synchronous function lambda_sync. When you don't need to know the result of the Lambda function before moving on to another action, use the asynchronous function lambda_async.
You can also use the activate_all_roles_on_login DB cluster parameter to automatically activate all roles when a user connects to a DB instance. When this parameter is set, you don't have to call the SET ROLE statement explicitly to activate a role.

Note
When you use the role technique in Aurora MySQL version 3, you also activate the role by using the SET ROLE role_name or SET ROLE ALL statement. If you aren't familiar with the MySQL 8.0 role system, you can learn more in Role-based privilege model. You can also find more details in Using roles in the MySQL Reference Manual.
This only applies to the current active session. When you reconnect, you have to run the SET ROLE statement again to grant privileges. For more information, see SET ROLE statement in the MySQL Reference Manual.
Syntax for the lambda_async function
You invoke the lambda_async function asynchronously with the Event invocation type. The function returns the result of the Lambda invocation in a JSON payload. The function has the following syntax.
lambda_async ( lambda_function_ARN, JSON_payload )
Parameters for the lambda_async function
The lambda_async function has the following parameters.
| Parameter | Description |
| lambda_function_ARN | The Amazon Resource Name (ARN) of the Lambda function to invoke. |
| JSON_payload | The payload for the invoked Lambda function, in JSON format. |
Aurora MySQL version 3 supports the JSON parsing functions from MySQL 8.0. JSON parsing isn't required when a Lambda function returns an atomic value, such as a number or a string.
Example for the lambda_async function
The following query based on lambda_async invokes the Lambda function BasicTestLambda asynchronously using the function ARN. The payload for the function is {"operation": "ping"}.
SELECT lambda_async(
'arn:aws:lambda:us-east-1:123456789012:function:BasicTestLambda',
'{"operation": "ping"}');
Invoking a Lambda function within a trigger
You can use triggers to call Lambda on data-modifying statements. The following example uses the lambda_async native function and stores the result in a variable.
SET @result=0;
DELIMITER //
CREATE TRIGGER myFirstTrigger
AFTER INSERT
ON Test_trigger FOR EACH ROW
BEGIN
SELECT lambda_async(
'arn:aws:lambda:us-east-1:123456789012:function:BasicTestLambda',
'{"operation": "ping"}')
INTO @result;
END; //
DELIMITER ;
Note
Triggers aren't run once per SQL statement, but once per row modified, one row at a time. When a trigger runs, the process is synchronous. The data-modifying statement only returns when the trigger completes.
Be careful when invoking an AWS Lambda function from triggers on tables that experience high write traffic. INSERT, UPDATE, and DELETE triggers are activated per row. A write-heavy workload on a table with INSERT, UPDATE, or DELETE triggers results in a large number of calls to the Lambda function.
As aforementioned, the triggers are only for UPDATE, and DELETE in my scenario.
Create the first trigger for UPDATE.
DROP TRIGGER IF EXISTS To_Lambda_Trigger_Update;
SET @result=0;
DELIMITER ;;
CREATE TRIGGER To_Lambda_Trigger_Update
AFTER UPDATE
ON [table_name]
FOR EACH ROW
BEGIN
SELECT lambda_async(
'arn:aws:lambda:us-west-2:111122223333:function:<Lambda function name>',
CONCAT(
'{ "action" : "UPDATE"',', "id" : "', NEW.id, '"}'
)
)
INTO @result;
END;
;;
DELIMITER ;
Create the second trigger for DELETE.
DROP TRIGGER IF EXISTS To_Lambda_Trigger_Delete;
SET @result=0;
DELIMITER ;;
CREATE TRIGGER To_Lambda_Trigger_Delete
AFTER DELETE
ON [table_name]
FOR EACH ROW
BEGIN
SELECT lambda_async(
'arn:aws:lambda:us-west-2:111122223333:function:<Lambda function name>',
CONCAT(
'{ "action" : "DELETE"',', "id" : "', OLD.id, '"}'
)
)
INTO @result;
END;
;;
DELIMITER ;
To verify this solution, I updated and deleted a few blog posts. On the Lambda function side, it got notified with necessary information.
The following Python code is an example for reference.
import json
def lambda_handler(event, context):
print(event["action"], event["id"])
# Handle the event
...
return {
'statusCode': 200,
'body': json.dumps(...)
}
References
Invoking a Lambda function from an Amazon Aurora MySQL DB cluster