Amazon Athena for Apache Spark
This feature is annouced on re:invent 2022. This blog post is a follow up of the leading post.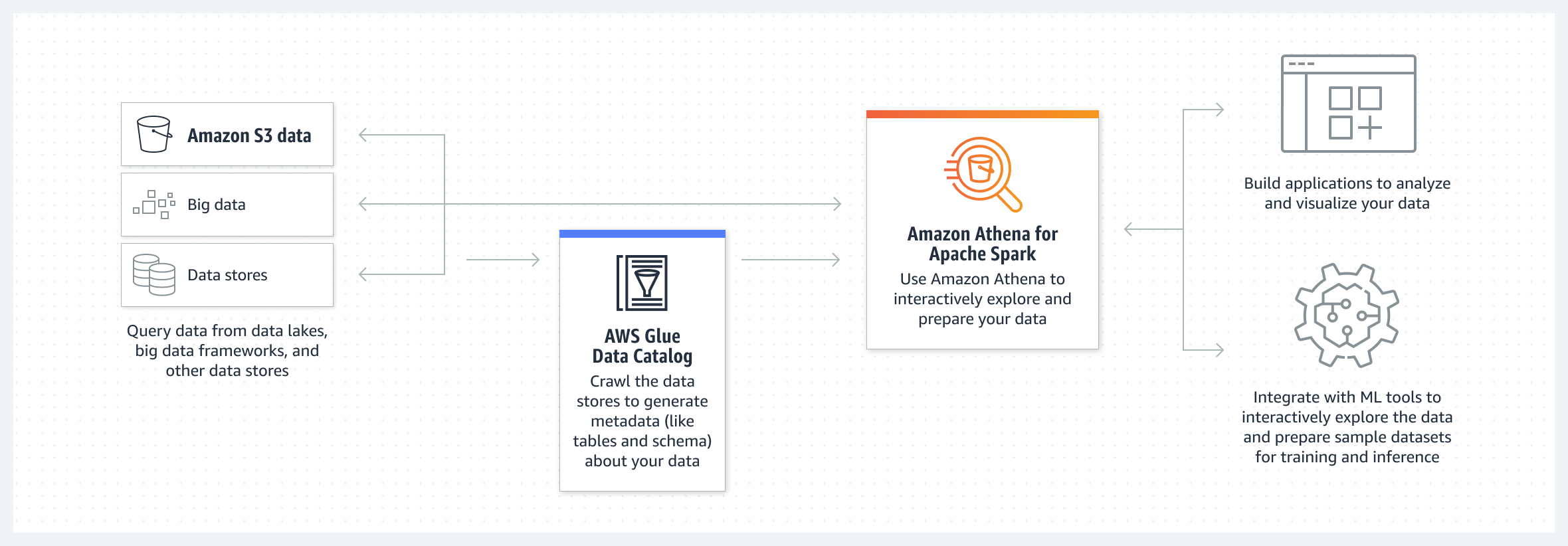
The first step is to create a workgroup. Athena workgroup helps separate workloads between users and applications.
To create a workgroup, from the Athena dashboard, select Create Workgroup.
On the next page, I give the name (here I name it as "Demo-Spark") and description for this workgroup.
On the same page, I can choose Apache Spark as the engine for Athena.
Check Turn on example notebook, which makes it easy to get started with Apache Spark inside Athena. I also have the option to encrypt Jupyter notebooks managed by Athena or use a KMS key.
Specify a service role with appropriate permissions to be used inside a Jupyter notebook.
Policy 1:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AccessPublicS3Buckets",
"Effect": "Allow",
"Action": [
"s3:GetObject"
],
"Resource": "arn:aws:s3:::athena-examples-us-east-1/notebooks/*"
},
{
"Sid": "GlueReadDatabases",
"Effect": "Allow",
"Action": [
"glue:GetDatabases"
],
"Resource": "arn:aws:glue:us-west-2:<111122223333>:*"
},
{
"Sid": "GlueReadDatabase",
"Effect": "Allow",
"Action": [
"glue:GetDatabase",
"glue:GetTable",
"glue:GetTables",
"glue:GetPartition",
"glue:GetPartitions"
],
"Resource": [
"arn:aws:glue:us-west-2:<111122223333>:catalog",
"arn:aws:glue:us-west-2:<111122223333>:database/spark_demo_database",
"arn:aws:glue:us-west-2:<111122223333>:table/spark_demo_database/*",
"arn:aws:glue:us-west-2:<111122223333>:database/default"
]
},
{
"Sid": "GlueCreateDatabase",
"Effect": "Allow",
"Action": [
"glue:CreateDatabase"
],
"Resource": [
"arn:aws:glue:us-west-2:<111122223333>:database/default",
"arn:aws:glue:us-west-2:<111122223333>:catalog",
"arn:aws:glue:us-west-2:<111122223333>:database/spark_demo_database"
]
},
{
"Sid": "GlueDeleteDatabase",
"Effect": "Allow",
"Action": "glue:DeleteDatabase",
"Resource": [
"arn:aws:glue:us-west-2:<111122223333>:catalog",
"arn:aws:glue:us-west-2:<111122223333>:database/spark_demo_database",
"arn:aws:glue:us-west-2:<111122223333>:table/spark_demo_database/*",
"arn:aws:glue:us-west-2:<111122223333>:userDefinedFunction/spark_demo_database/*"
]
},
{
"Sid": "GlueCreateDeleteTable",
"Effect": "Allow",
"Action": [
"glue:CreateTable",
"glue:DeleteTable"
],
"Resource": [
"arn:aws:glue:us-west-2:<111122223333>:catalog",
"arn:aws:glue:us-west-2:<111122223333>:database/spark_demo_database",
"arn:aws:glue:us-west-2:<111122223333>:table/spark_demo_database/select_taxi_table"
]
}
]
}
Policy 2:{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:ListBucket",
"s3:DeleteObject",
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::aws-athena-query-results-us-west-2-<111122223333>/*",
"arn:aws:s3:::aws-athena-query-results-us-west-2-<111122223333>"
]
},
{
"Effect": "Allow",
"Action": [
"athena:GetWorkGroup",
"athena:TerminateSession",
"athena:GetSession",
"athena:GetSessionStatus",
"athena:ListSessions",
"athena:StartCalculationExecution",
"athena:GetCalculationExecutionCode",
"athena:StopCalculationExecution",
"athena:ListCalculationExecutions",
"athena:GetCalculationExecution",
"athena:GetCalculationExecutionStatus",
"athena:ListExecutors",
"athena:ExportNotebook",
"athena:UpdateNotebook"
],
"Resource": "arn:aws:athena:us-west-2:<111122223333>:workgroup/Demo-Spark"
},
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"logs:CreateLogStream",
"logs:DescribeLogStreams",
"logs:CreateLogGroup",
"logs:PutLogEvents"
],
"Resource": [
"arn:aws:logs:us-west-2:<111122223333>:log-group:/aws-athena:*",
"arn:aws:logs:us-west-2:<111122223333>:log-group:/aws-athena*:log-stream:*"
]
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": "logs:DescribeLogGroups",
"Resource": "arn:aws:logs:us-west-2:<111122223333>:log-group:*"
},
{
"Sid": "VisualEditor2",
"Effect": "Allow",
"Action": [
"cloudwatch:PutMetricData"
],
"Resource": "*",
"Condition": {
"StringEquals": {
"cloudwatch:namespace": "AmazonAthenaForApacheSpark"
}
}
}
]
}
Trust relationship:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "athena.amazonaws.com"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"aws:SourceAccount": "<111122223333>"
},
"ArnLike": {
"aws:SourceArn": "arn:aws:athena:us-west-2:<111122223333>:workgroup/Demo-Spark"
}
}
}
]
}
Define a S3 bucket to store calculation results from the Jupyter notebook.
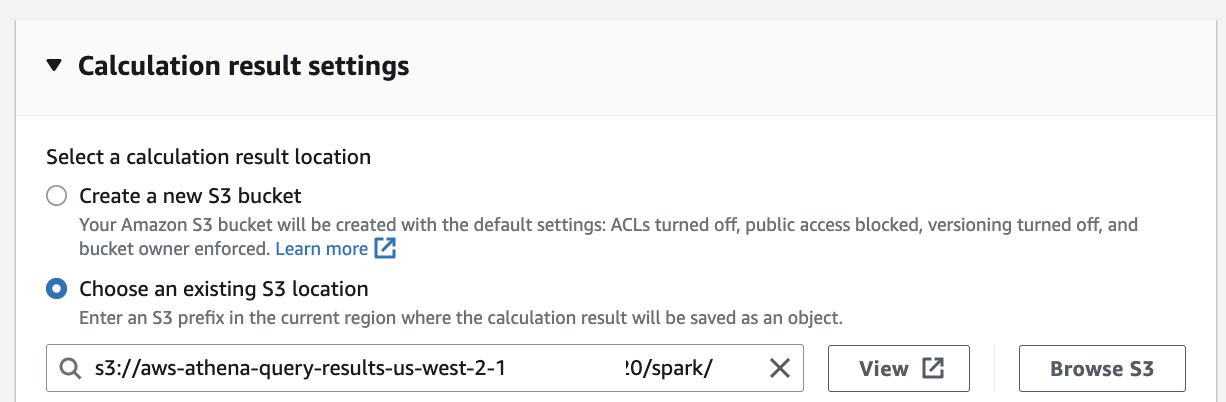
Create workgroup.
To see the details of this workgroup, select the link from the workgroup. Since I also checked the Turn on example notebook when creating this workgroup, I have a Jupyter notebook to help me get started.]
Amazon Athena also provides flexibility for me to import existing notebooks that I can upload from local file with "Import file", or create new notebooks from scratch by selecting Create notebook.
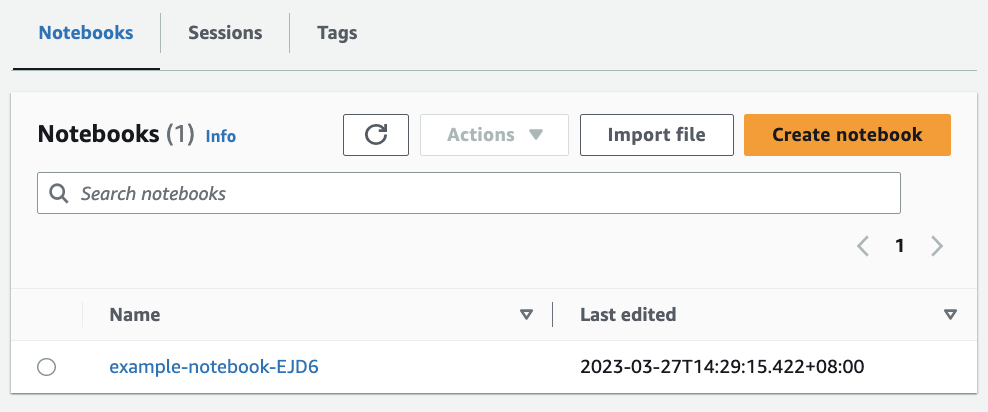
Select the Jupyter notebook example, start building my Apache Spark application.
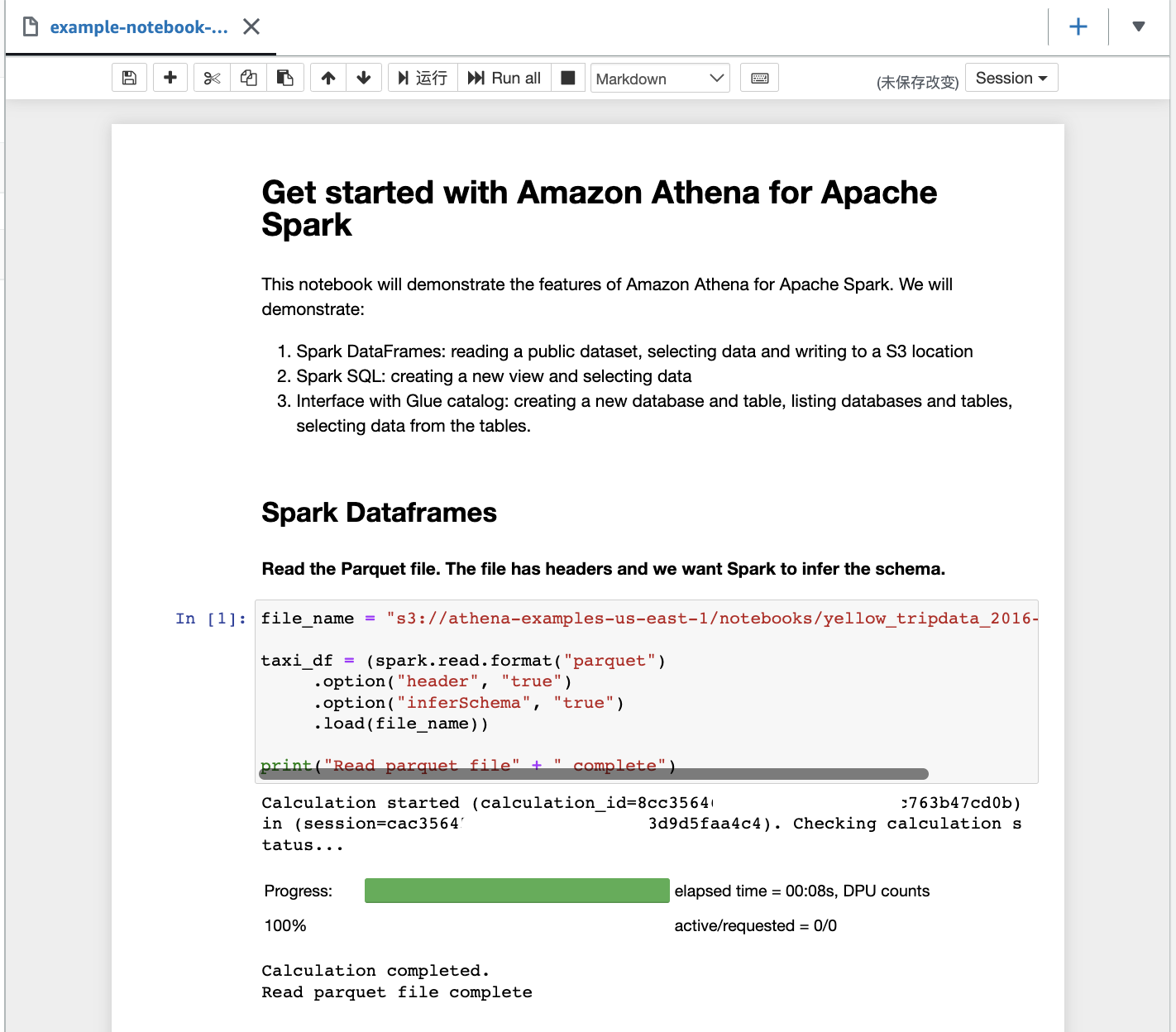
When I run a Jupyter notebook, it automatically creates a session in the workgroup. Subsequently, each time I run a calculation inside the Jupyter notebook, all results will be recorded in the session. This way, Athena provides me with full information to review each calculation by selecting Calculation ID, which took me to the Calculation details page. Here, I can review the Code and also Results for the calculation.
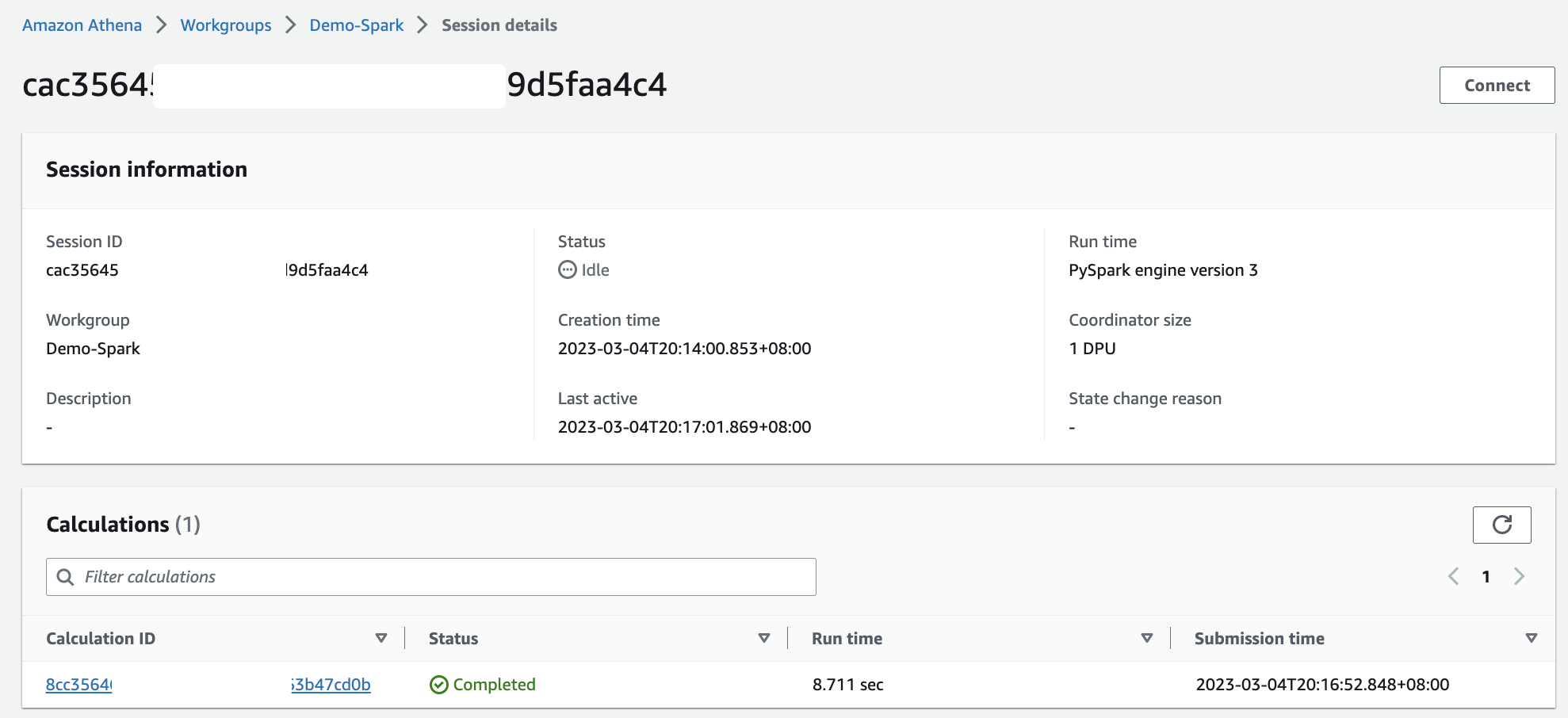
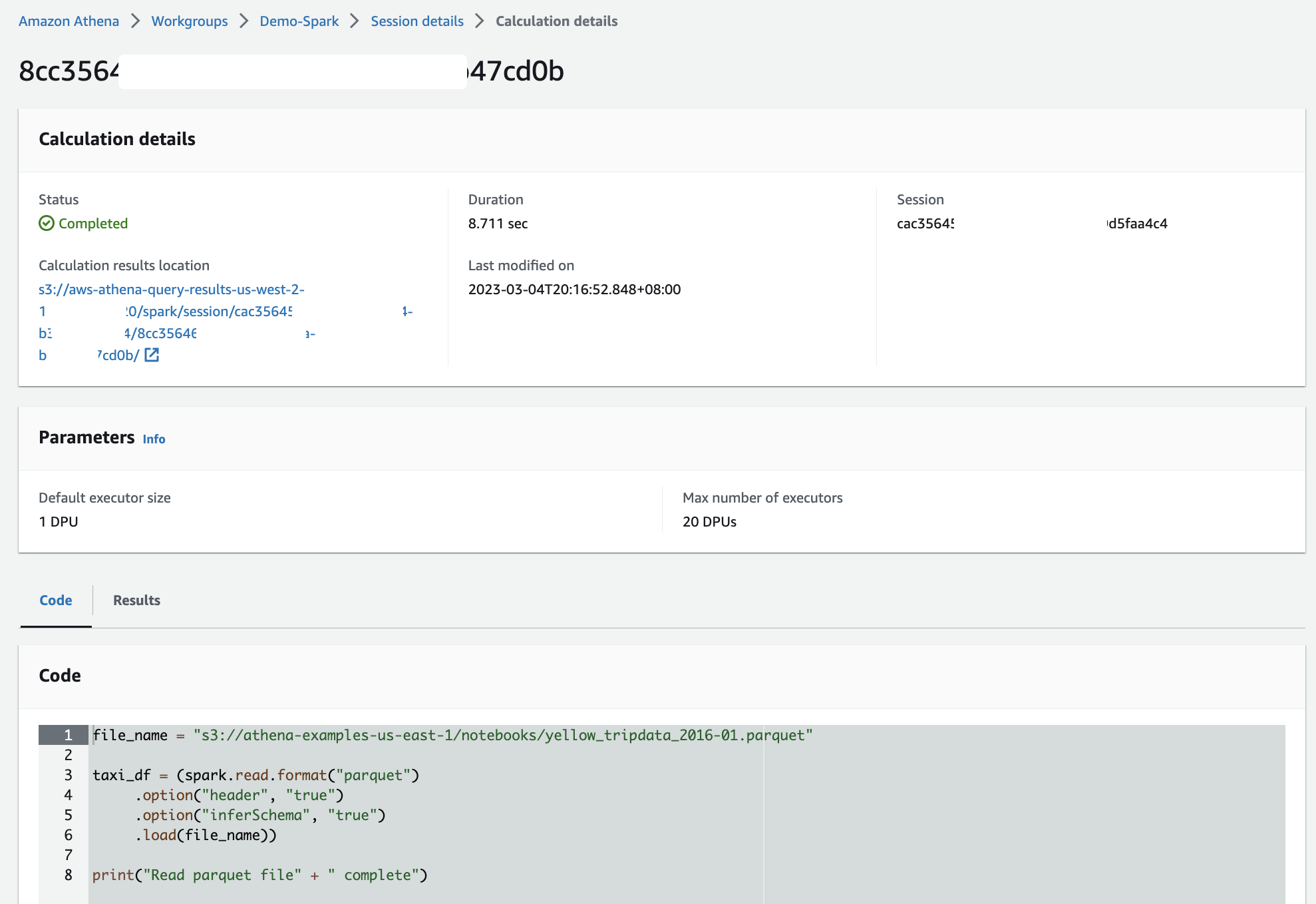
In the session, I can adjust the Coordinator size and Executor size, with 1 data processing unit (DPU) by default. A DPU consists of 4 vCPU and 16 GB of RAM. Changing to a larger DPU allows me to process tasks faster if I have complex calculations.
References
New — Amazon Athena for Apache Spark