Version control your scripts in Glue Studio using GitHub
AWS Glue offers integration with GitHub. Thanks to this integration, we can:
- incorporate DevOps practices
- version control Scala or Python (PySpark) code
- use automation tools to deploy AWS Glue jobs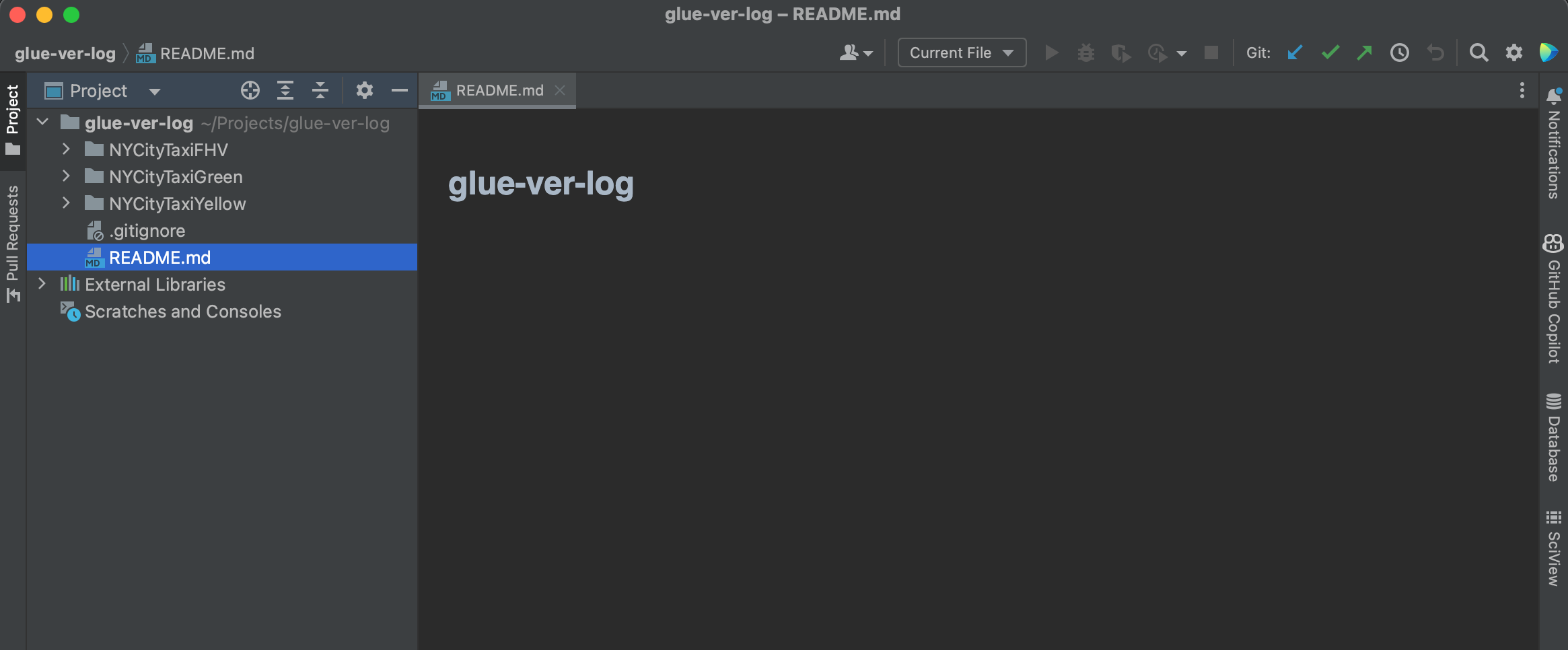
AWS Glue Studio's visual editor also supports parameterizing data sources and targets for transparent deployments between environments. But in this post we are not covering these features for conciseness.
From here I will start demostrate this feature.
In GitHub, create a new repo and a new branch for it.
Create personal access token it will be used in later steps.
On the Version Control tab, for Version control system, choose Github.
For Personal access token, enter your GitHub token.
For Repository owner, enter the owner of your GitHub account.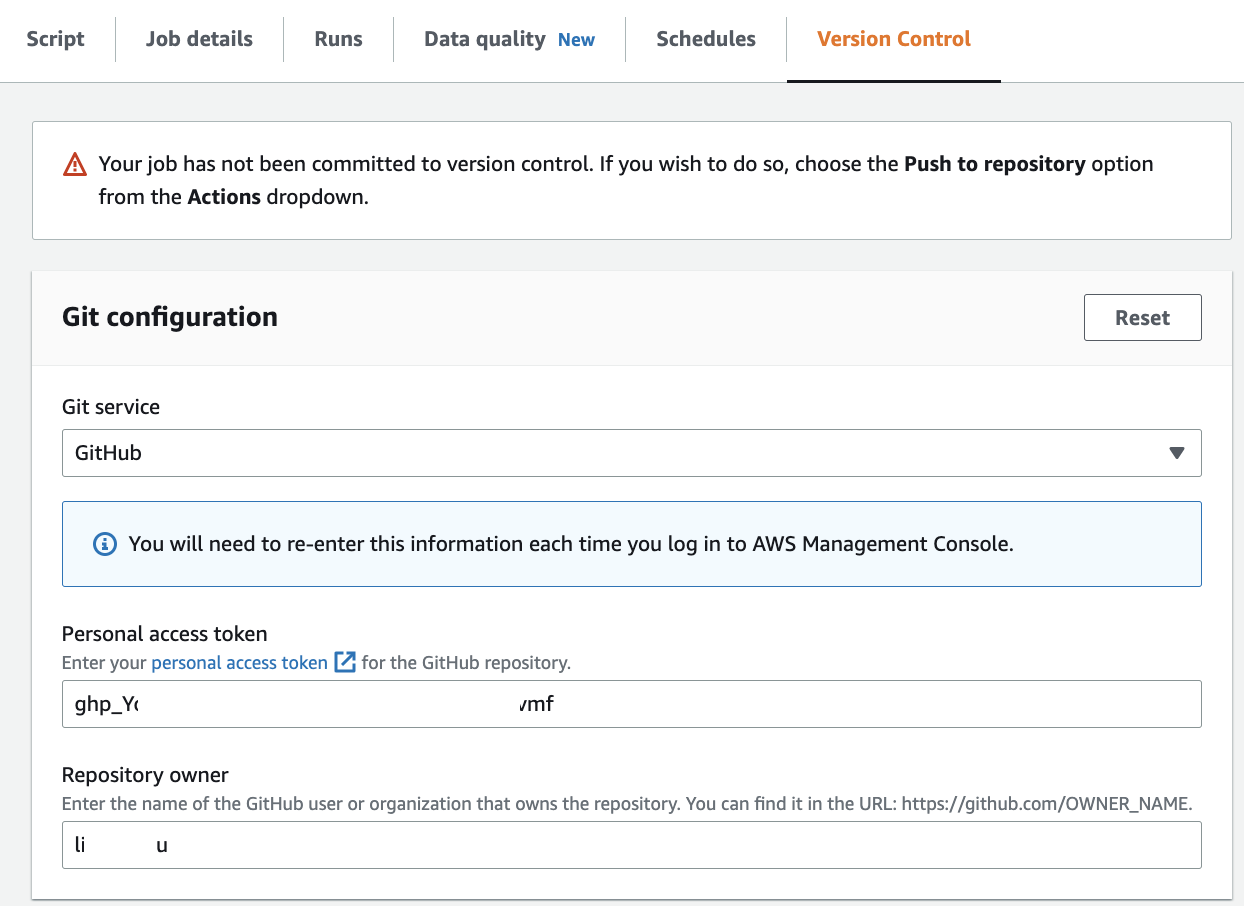
Click Save.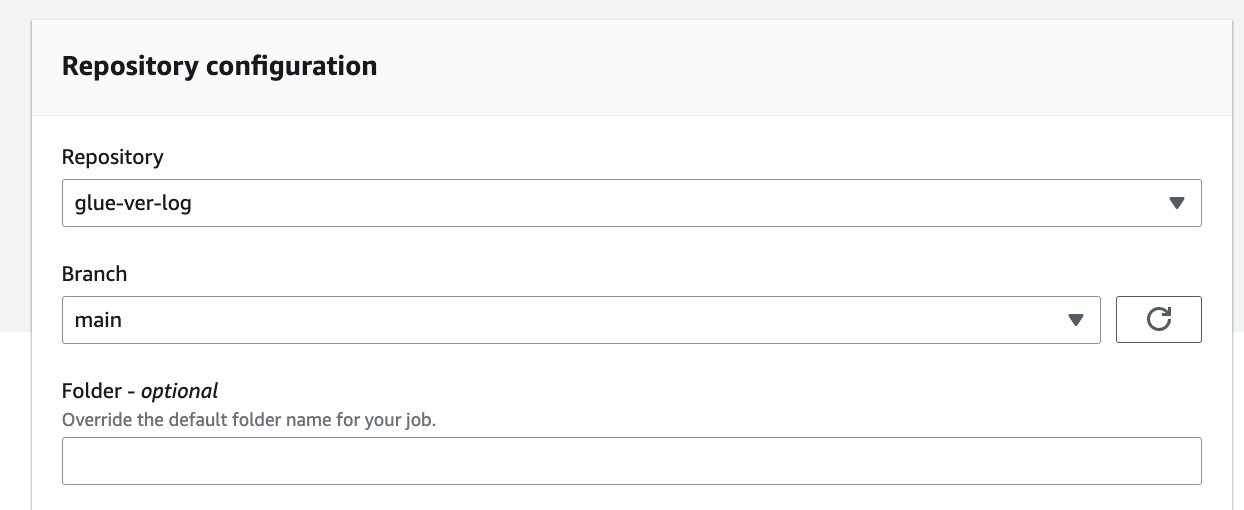
Push to the repository
Now the job can be pushed to the remote repository. On the Actions menu, choose Push to repository.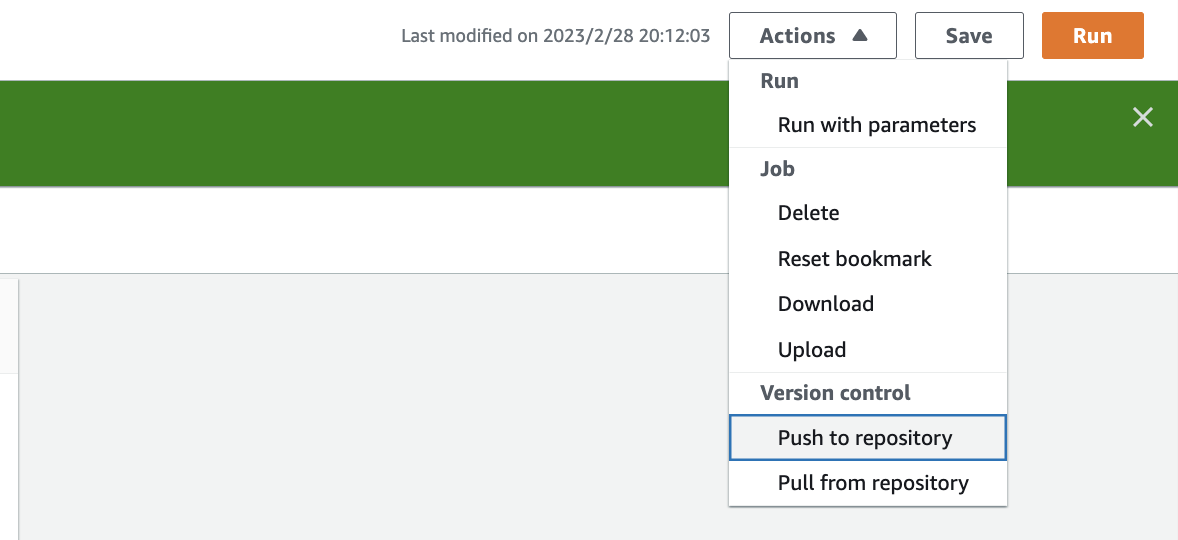
Choose Confirm to confirm the operation.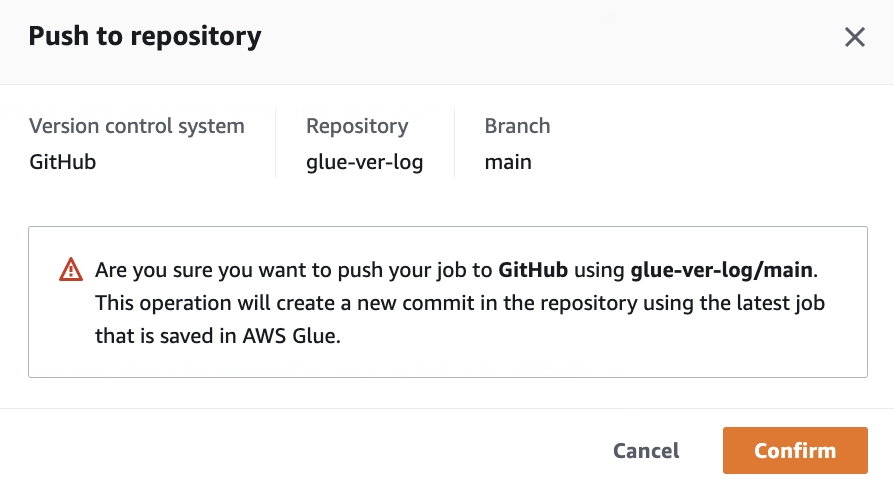
Pull from the repository
Clone the Git repo to your local development environment.
Under the folder which is named by the Glue job name, choose the <Glue-job-name>.json file. Set the MaxRetries parameter to 1. Commit and push the code to GitHub.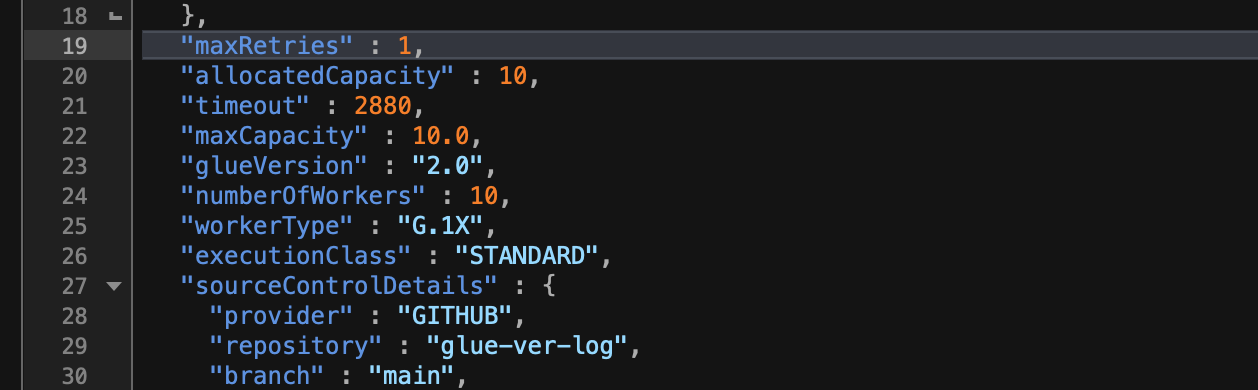
Return to the AWS Glue console and on the Actions menu, choose Pull from repository. Choose Confirm.
On the Job details tab, you can see that the value for Number of retries is 1. PS: The default value of this retry field is 0.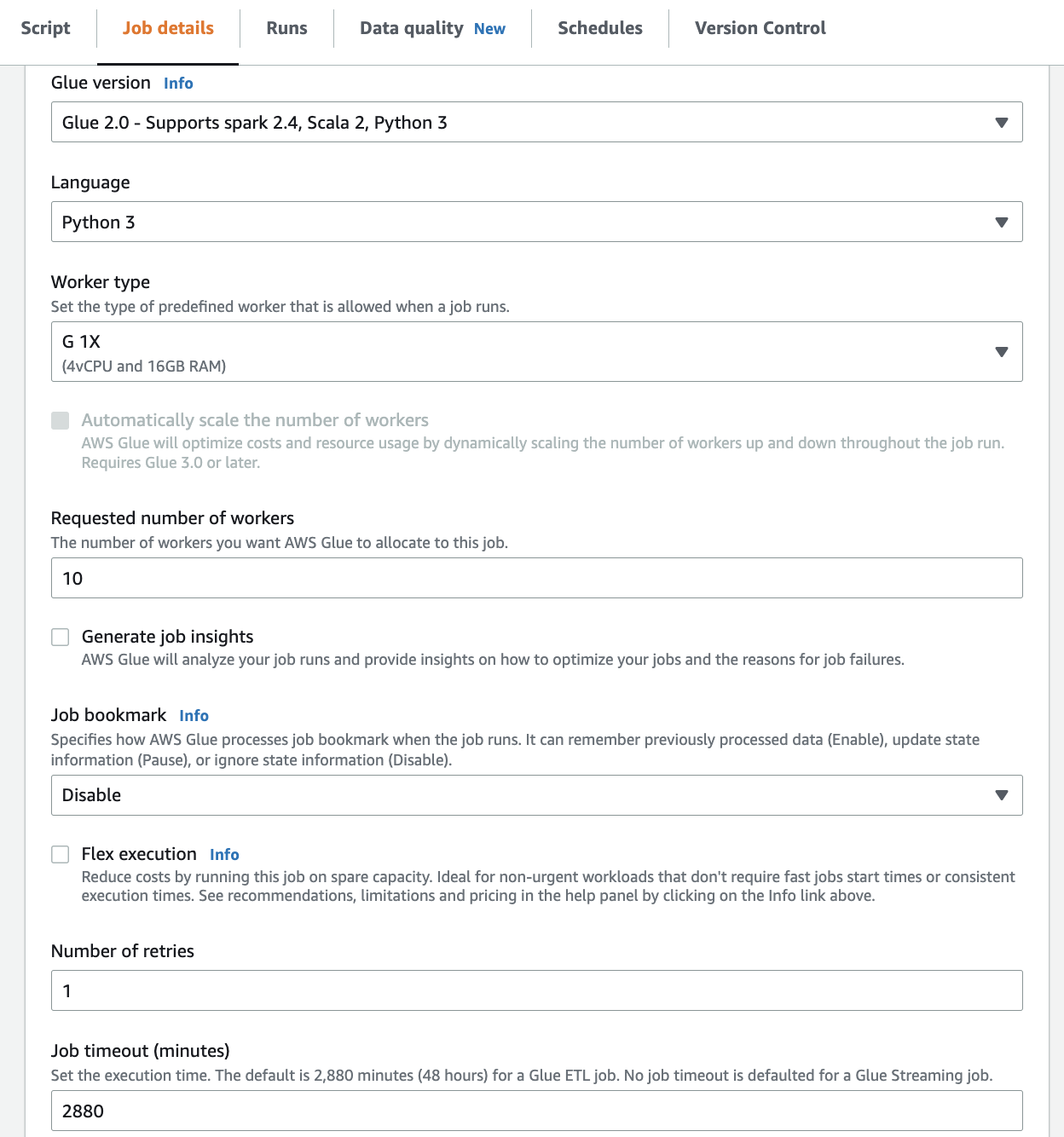
You can push scripts and code of multiple jobs to the same GitHub repo. The project folder structure will be as below.
. ├── NYCityTaxiFHV │ ├── NYCityTaxiFHV │ └── NYCityTaxiFHV.json ├── NYCityTaxiGreen │ ├── NYCityTaxiGreen │ └── NYCityTaxiGreen.json ├── NYCityTaxiYellow │ ├── NYCityTaxiYellow │ └── NYCityTaxiYellow.json └── README.md 3 directories, 7 files
References
https://aws.amazon.com/cn/blogs/big-data/code-versioning-using-aws-glue-studio-and-github/