AWS re:Invent 2022 - [NEW LAUNCH] Amazon DataZone – Democratize data with governance (ANT344)
Agenda
- Common customer data challenges
- Amazon DataZone key capabilities and features
- Amazon DataZone's supported data architectures
[]
Common themes we hear from our customers
[3:39]
Introducing Amazon DataZone
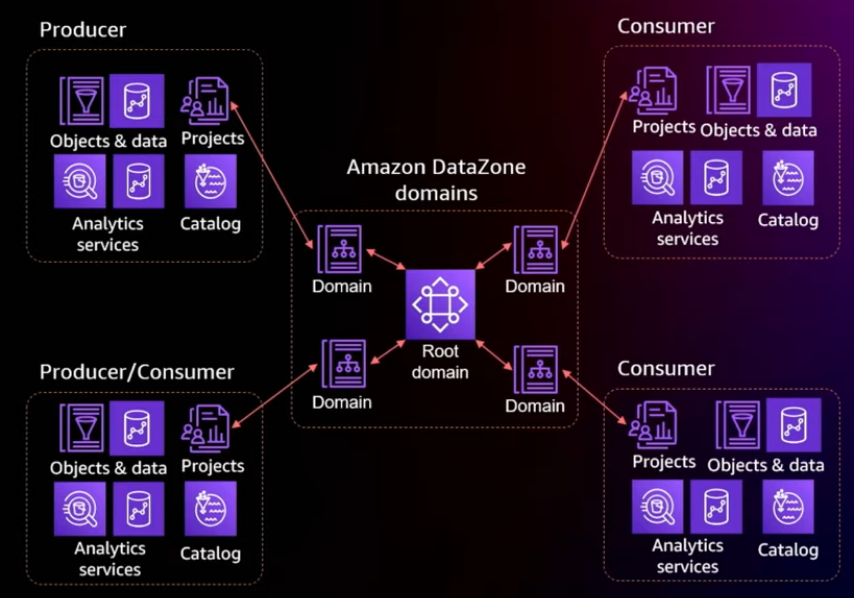
Unlock data across organizational boundaries with built-in governance
[4:05]
Producers and consumers: Campaign analysis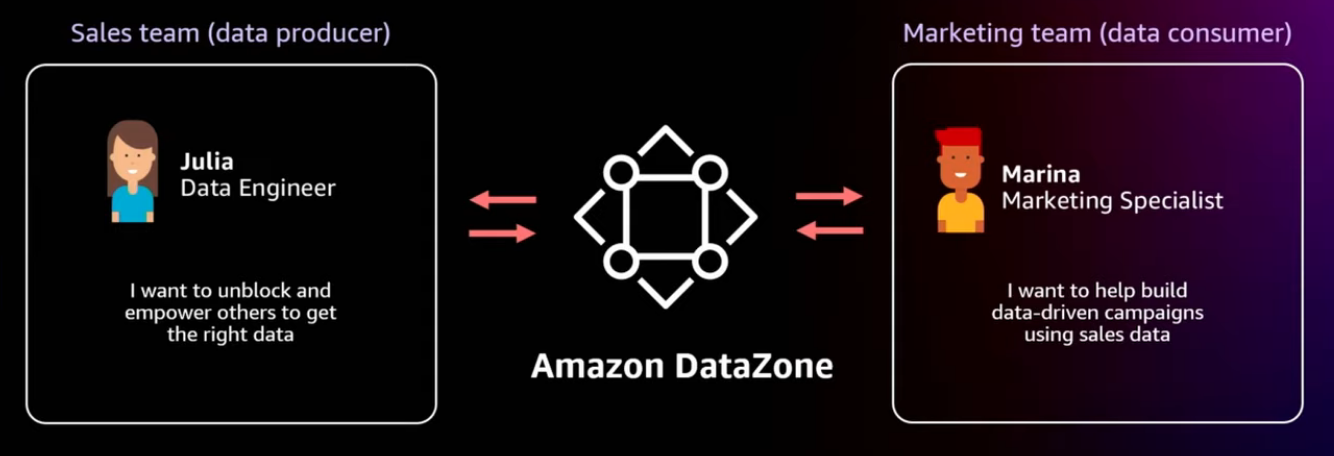
[6:11]
Amazon DataZone: Key capabilities and features
[6:35]
Core components of Amazon DataZone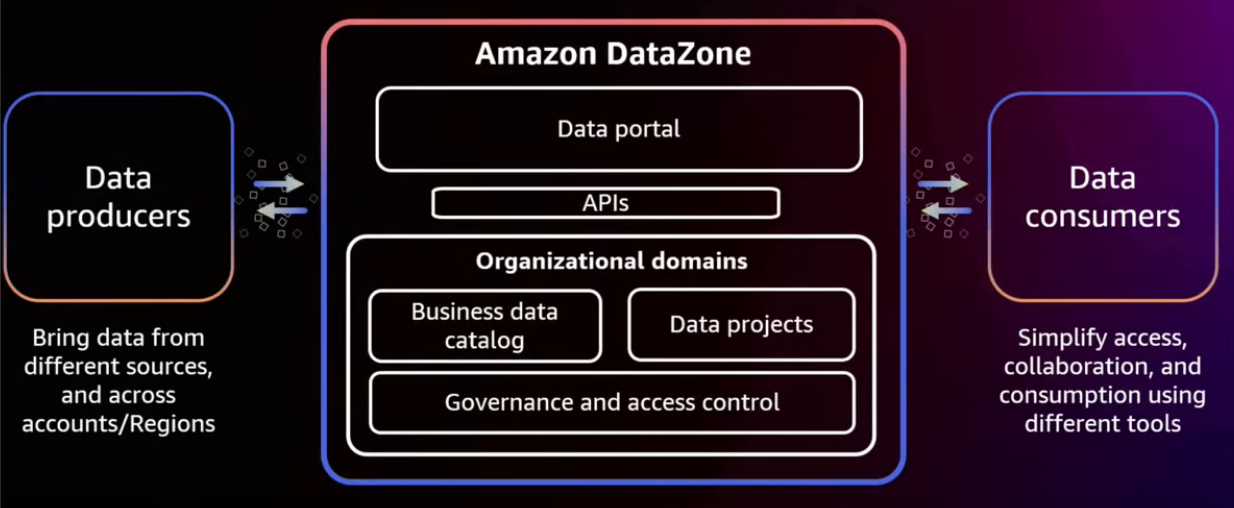
[8:57]
Amazon DataZone data portal
-
-
-
[9:58]
Enterprise-wide data search
Find and discover the right data faster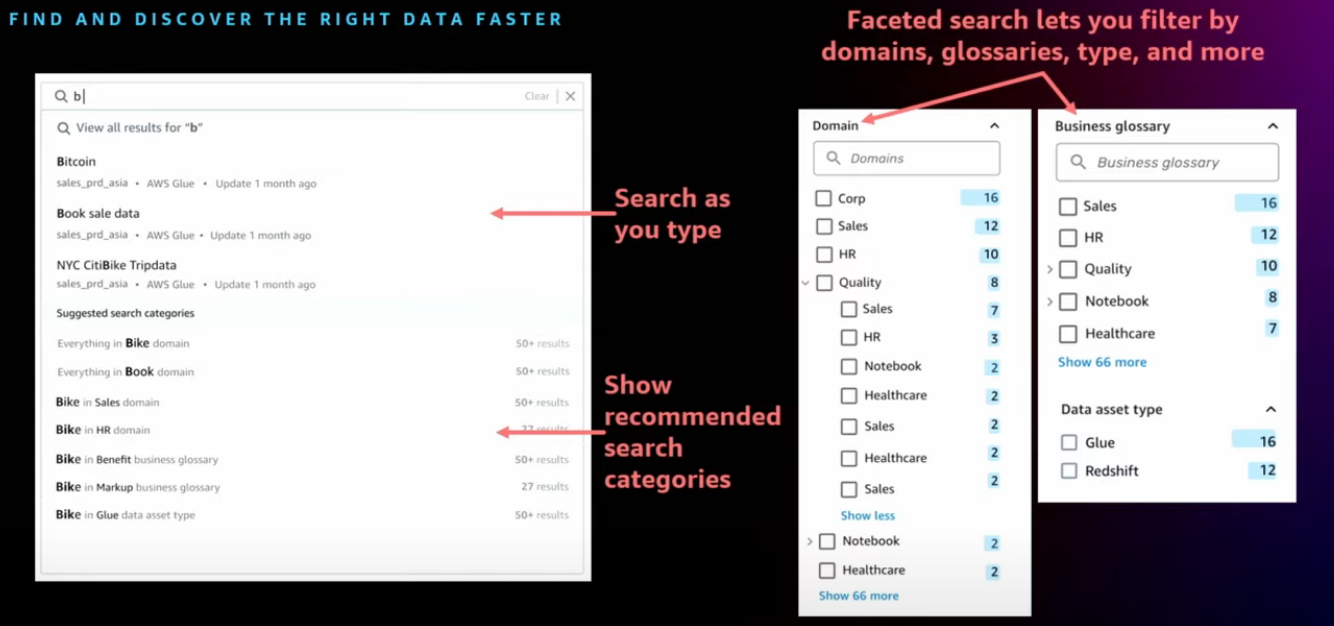
[10:45]
Business organization is complex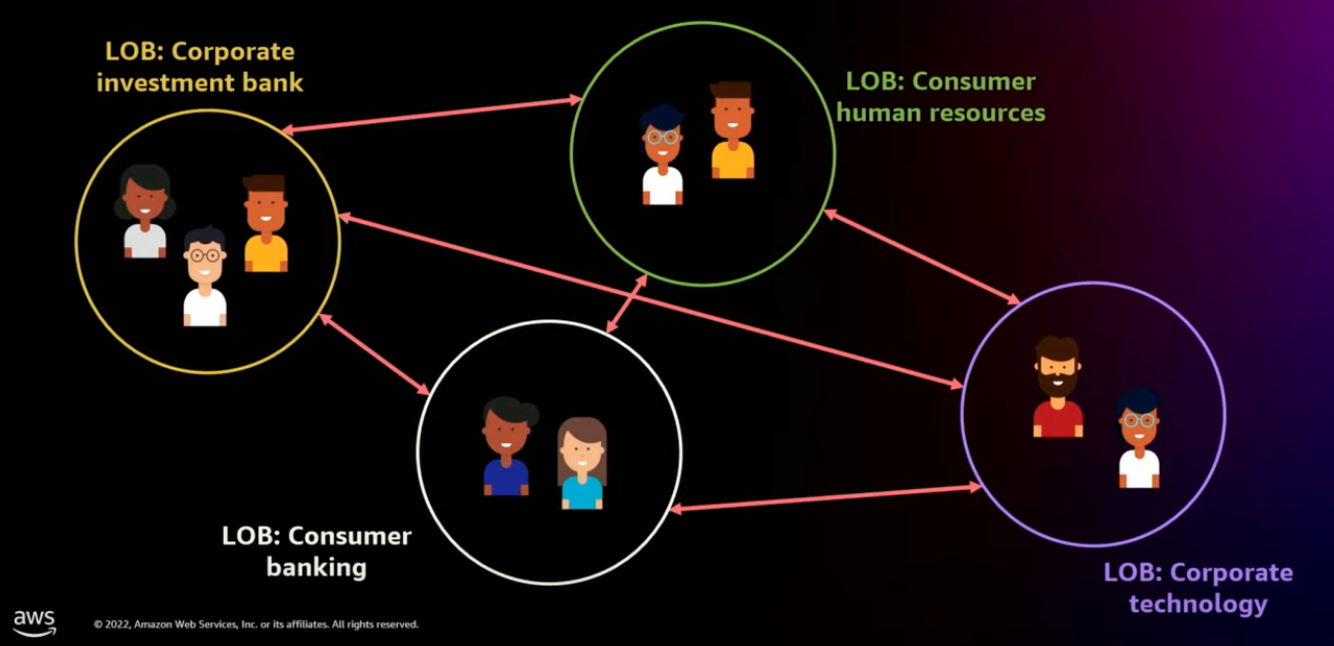
[11:25]
Domains that reflect your organization
Data zone introduces a feature called Domain, which is precisely this umbrella capability where users can come catalog their data with, you know, rich business context. And the data can reside in any account, any region, any supported region.
You can also manage consistency and standards using mechanisms such as metadata forms, business glossary.
Users also are under some kind of a discipline that's enforced within the domain where they have to abide by the standards as set by the data experts.
Each organization can also represent their own organizational hierarchy with the domain using sub-domains.
You can designate some of the experts as data stewards and they set the standards for intake policies as well as all of the governance around each of their own domain, and they can make sure that the quality of the metadata is consistent and usable for end users.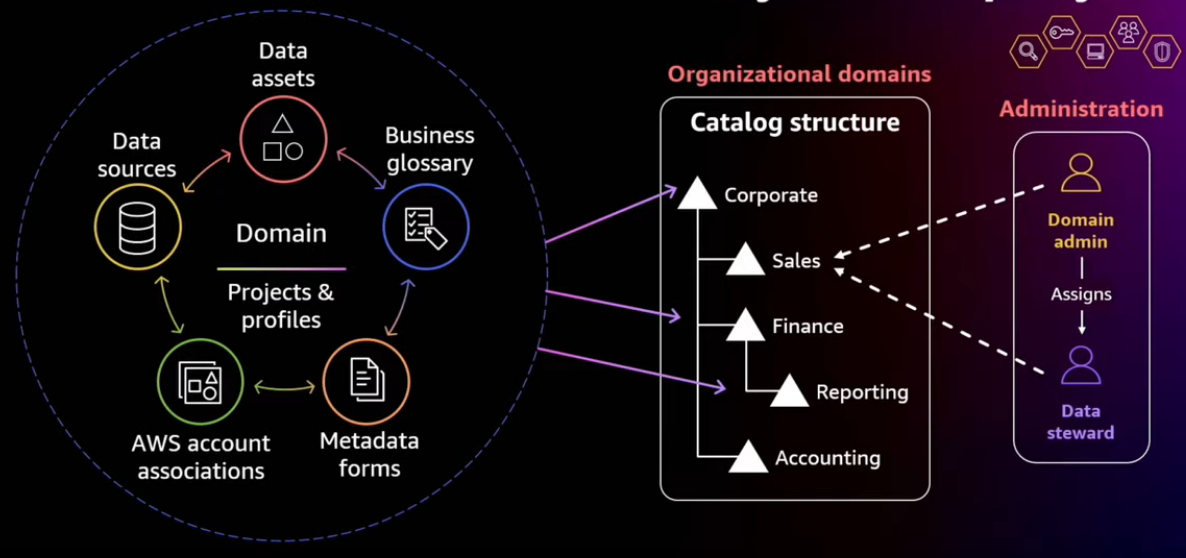
[13:27]
Catalog all of your data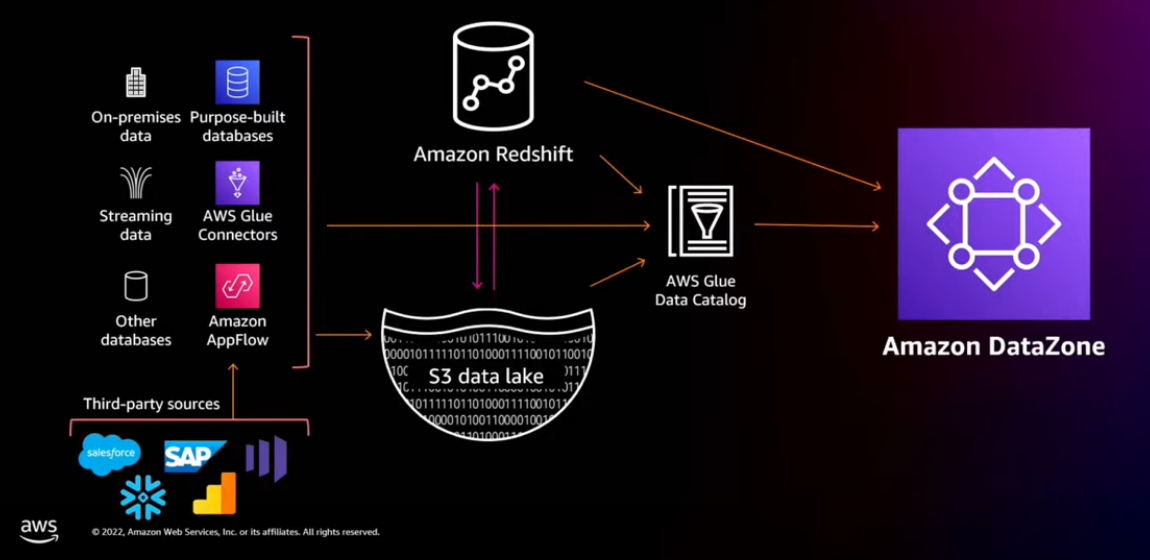
[14:49]
Data assets in the catalog
Build a common language for business and technical users to communicate easily and collaborate effectively
Behind the scenes, the lowest granularity of the asset in a business data catalog is called a data asset. You can think of those as tables, files, dashboards, and so on.
Each one of them have a technical information such as table name, table description, column name, column types, and the, you know, column descriptions and so on. And further, you can have extensible business metadata such as business descriptions, alias, you know, sensitivity of the data, classification of the data and so on. So users who are looking for data understand this data in the context or in the language that they're familiar with.
With this, the data stewards also have an ability to create what we call as metadata forms. Metadata forms is really some type of an, you can think of it as an intake form where your data stewards can set up recommended or required fields, that all of the publishers into the catalog must abide by or they must follow those rules and anything that's required must be provided. And they also may have recommended values for these things.
A data steward may also update those forms to make sure that the, you know, metadata is rich and usable.
A sales domain data steward may set up a metadata form and make sure that sales region is a must for any data asset that comes into the catalog. And then they may also recommend that publishers also provide, you know, other, you know, attributes such as sales, sales quarter and so on.
Further, you can also make sure that there is consistency in the values that they provide for each in a column in the metadata form. So some of those columns may be very sensitive or it's probably required for your business.
Data stewards can define business glossary 16:49 or a hierarchy of business glossary. In this case, you know, they have the regions that are predefined, 16:55 so users are expected to pick, that's the only option they have, is to pick from one of those predefined business glossary.
This helps with a couple of things, right?
One, of course the consistency of the metadata that you can see in your catalog.
Second, it helps, you know, to have this terms relate with each other, so users can understand this data in the context as they understand data.
For example, some of our own internal use cases, we see the word revenue being used differently 17:27 by different groups. So they can make sure that there is a business glossary that actually, you know, 17:32 refers to that particular field and explain that further for, you know, 17:37 better understandability of data.
Thirdly, this also helps abstract away any technical jargon 17:45 for people who are trying to look for data in a language that they understand and not any call underscore ID and so on.
[17:55]
Simplified analytics for everyone
Data projects get data consumers analyzing data faster, removing technical complexity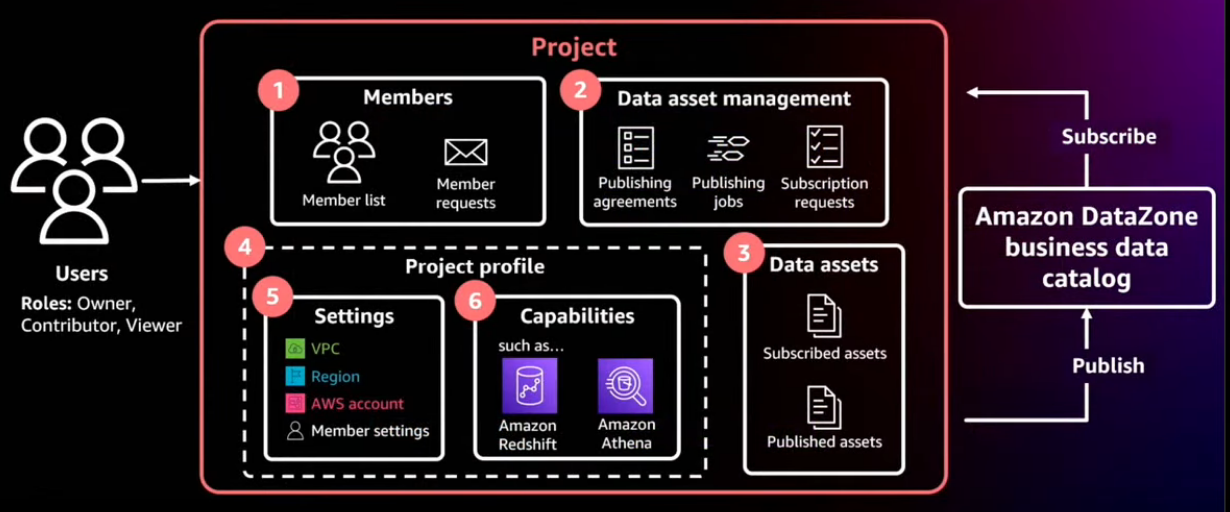
What is a workflow? Let's quickly take a, you know, quick peek at the workflow that helps users come and publish their data into the catalog in a self-service manner, or for users to come consume the data and, you know, work on the rest of their use cases.
A lot of customers that we talk to, now, they're all trying to come up with some way of organizing their data, their users and the tools and control access at a group level, so they don't have to deal with individual user access, understand why they're using the data, you know, what's your attention policy, how do you revoke and so on.
I think the thing to understand here is that any entitlement is actually given to the business context 19:18 of the business use case and users can be added and removed anytime. 19:24 And any access a user may have here is actually federated through the identity 19:30 of that project context or a business context. 19:35 Finally, you know, a project also gives the producers of the data 19:42 an ability to control the ownership of their own data in a completely, you know, decentralized manner 19:51 where each project member or each producer, the owner of the producer actually knows 19:57 who's requesting access, who's using, and make sure they can audit.
[20:04]
Query your data with deep links
Take your projects' data permissions with you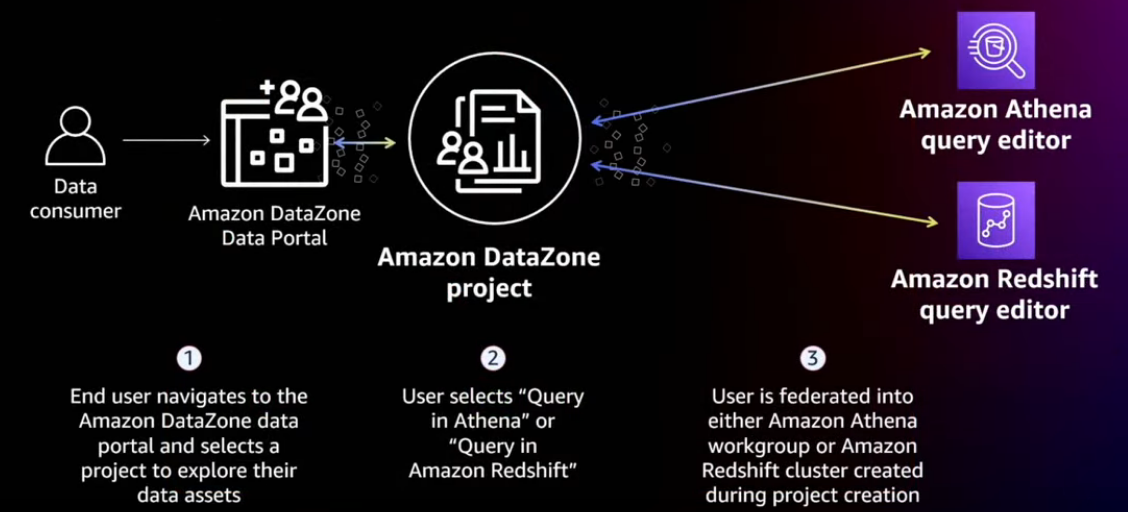
You know, we support multiple accounts, cross accounts. So within each account, you also, as you know, as a creator of the project, you have an ability to configure resources via what we call as capabilities, which gives you a seamless access into the tool where you potentially want to use the data.
And a user can log in into the portal, it'll click on the search, look for whatever data, and quickly make sure that they get the entitlement and further proceed to actually use the data and complete the end to end workflow, which, you know, speeds up working on the business use cases.
[21:09]
Amazon DataZone's supported data architectures
[21:34]
Data lakes and modern data architectures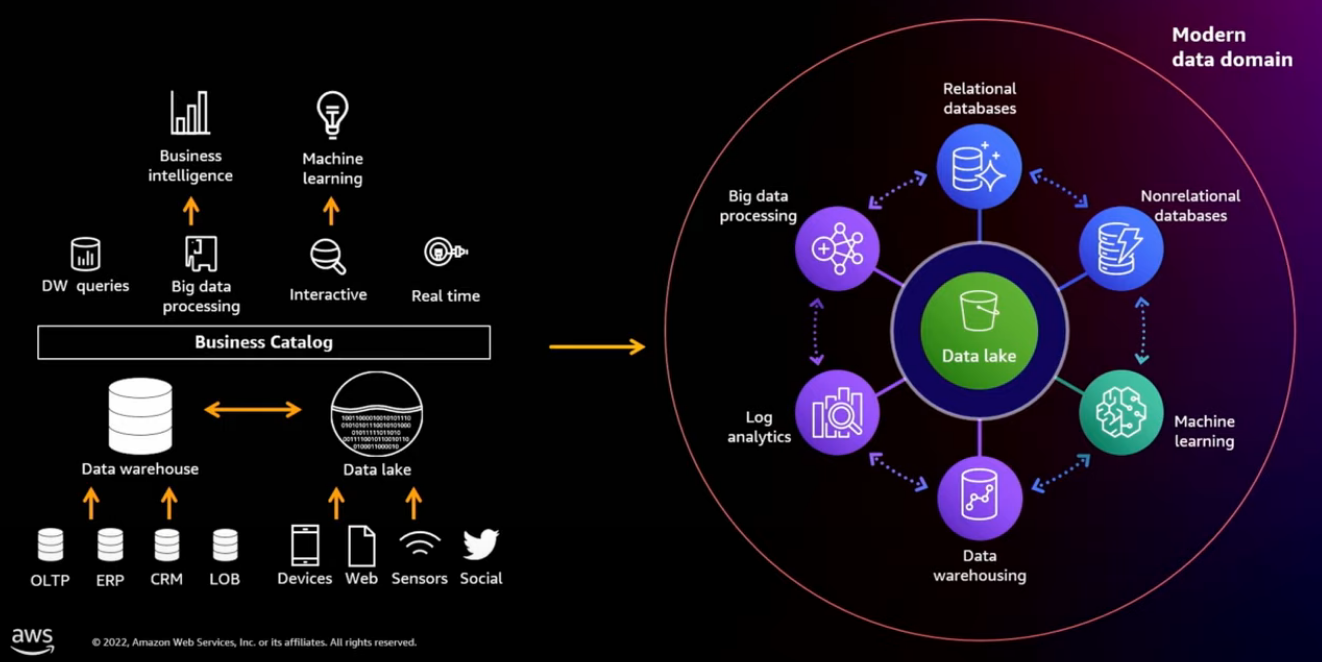
[22:45]
Accelerate data mesh with Amazon DataZone
Scale and remove bottlenecks to fully democratize data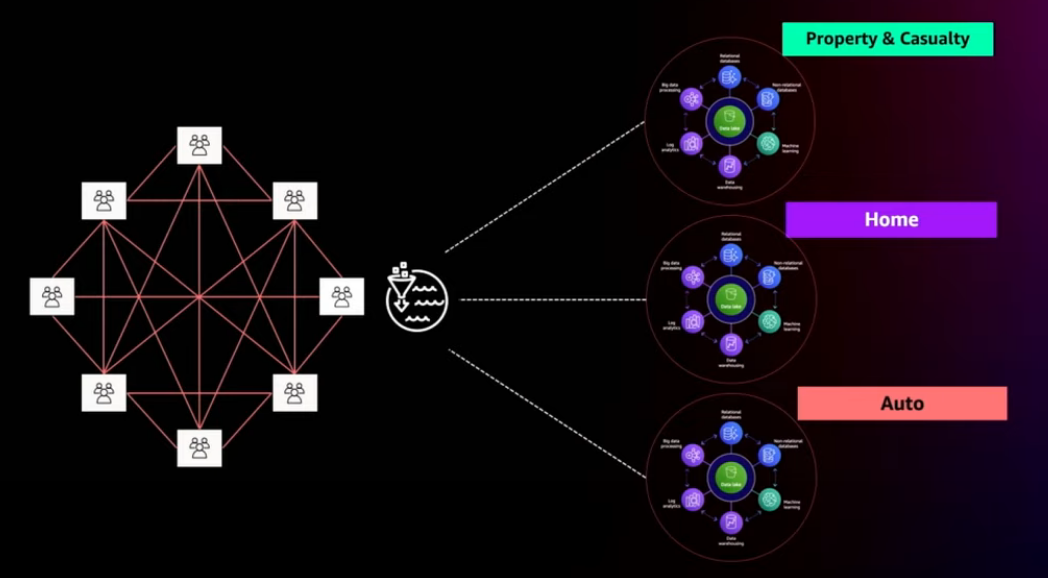
Principles:
- Decentralized ownership
- Federated governance
- Peer-to-peer data sharing
Peer-to-peer data sharing Data is shared directly from the producer to the consumer. There is no need to stage the data into a centralized staging area or a data lake or a data warehouse. This is a true end-to-end model in terms of data flow.
- Self-service infrastructure
These four principles allow us to remove bottlenecks 25:57 that are often found in centralized data lakes and data warehouses.
Let's examine a few architectural principles 24:05 that both the data mesh and data zones embrace.
[26:15]
Enable self-service analytics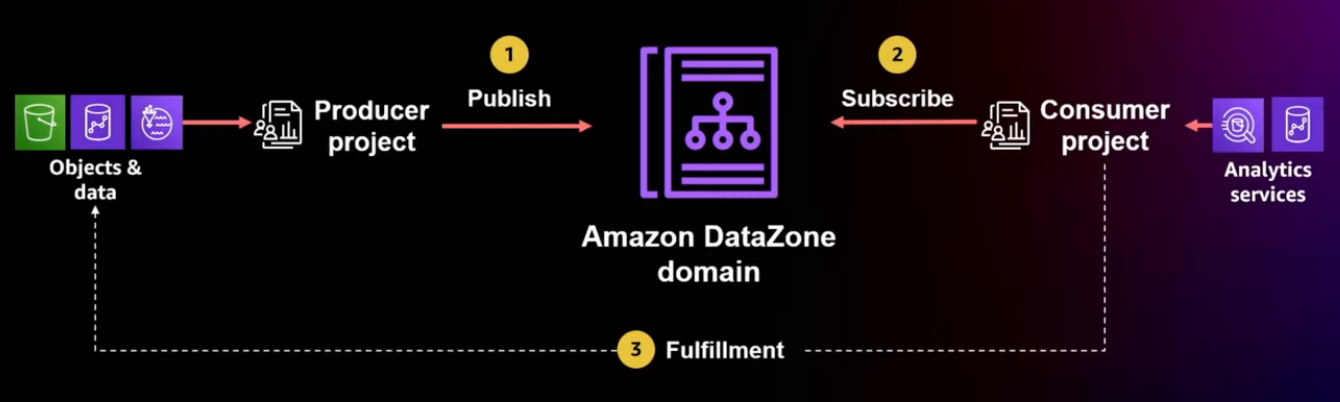
In the next three slides, we will take a deeper look into each of those workflows, publishing, subscribing and fulfillment.
[27:00]
Publishing agreements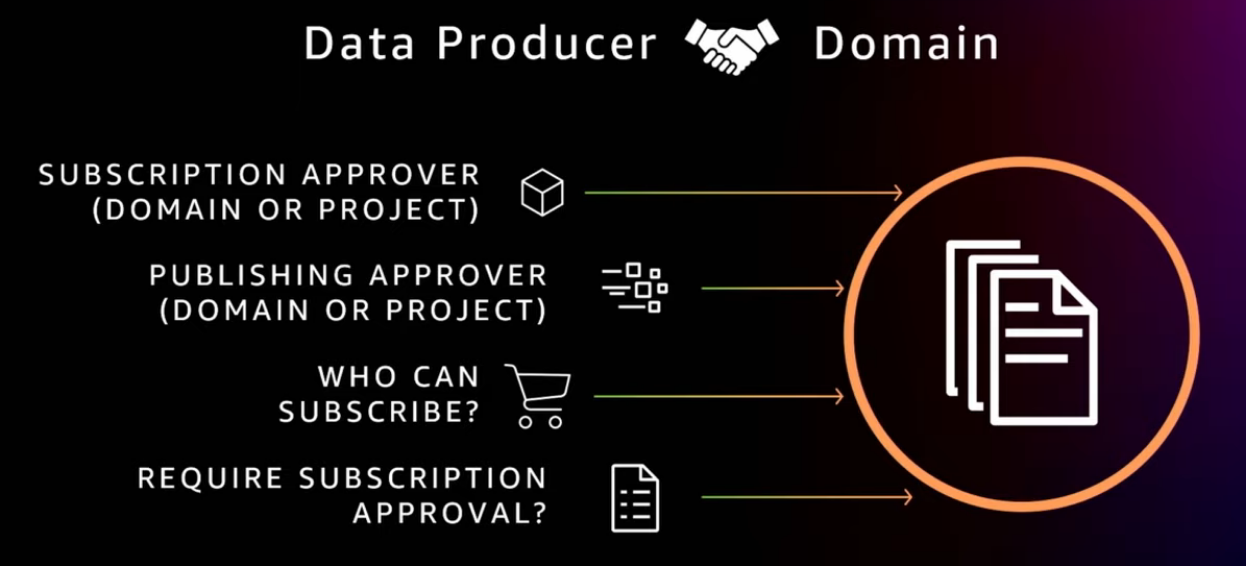
A data zone projects that want to publish data must first have a publishing, have a valid publishing agreement with a domain.
A publishing agreement is like a contract between the data producer and the catalog domain that defines the terms and conditions for publishing and subscribing.
Terms like who can publish, who can subscribe, what assets can be published, is authorization needed, and if authorization needed, who will be the authorizer? The publishing agreement can start from an agreement draft that the domain steward created and the final agreement will include the negotiated agreed terms between the publishing project and the catalog domain.
A category manager in our Amazon retail shop is very similar to a data domain steward. They have similar jobs. So let's assume that I'm the category manager for the TVs in Amazon and Shikha here is coming from a very wealthy family of TV manufacturers and she wants to sell her products through me.
My job is to make sure that my customer can go and find the products in my catalog and it's a high quality catalog. I, therefore, create an initial publishing agreement that requires a metadata form. And in that metadata form I'm going to ask simple questions.
What is the type of screen that you're going to sell for the TV? Is it a QLED, LCD, OLED and so on? I'm even going to create a business glossary with this standard terms to create higher quality.
The second field can be the type of the, 28:59 the size of the screen. Is it a 50 inch or 60 inch and so on, right? With the standard sizes.
I can also demand that you will sell the products in all the regions where I have customers.
This is the initial publishing agreement. When Shikha comes and wants to sell her products through me, she going to look at the agreement, she might accept the terms. We might negotiate. For example, she wants to sell it only in the US and Europe.
I can agree to that. And then that forms our final publishing agreement.
This enable federated governance where each domain defines the requirement for the publishing and subscription and at the same time, it leaves the details of how it is implemented to the producing project.
Now we have a publishing agreement. Now, let's see how the actual process of publishing data assets is.
[30:15]
Publishing data assets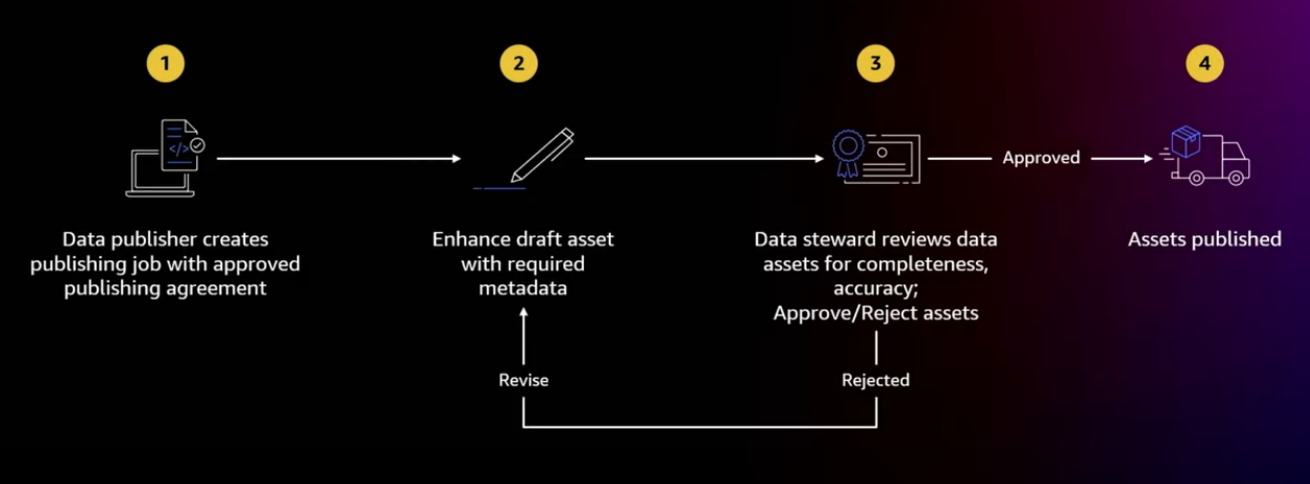
The process starts by creating a publishing job to curate metadata for selected set of physical assets.
This, for example, can be curating a set of golden tables from a Redshift data warehouse.
After the publishing job ran, draft assets are created and the data publisher adds additional metadata descriptions, annotations, and so on to improve the discovery experience as well as to meet the conditions that are agreed in the publishing agreement.
Once the required changes are made, the data publishers submits the request and the data steward can then review the data for completeness, accuracy, and then decide if to approve or reject it.
If they approve, the asset is then published in the catalog.
[31:05]
Subscribing to data assets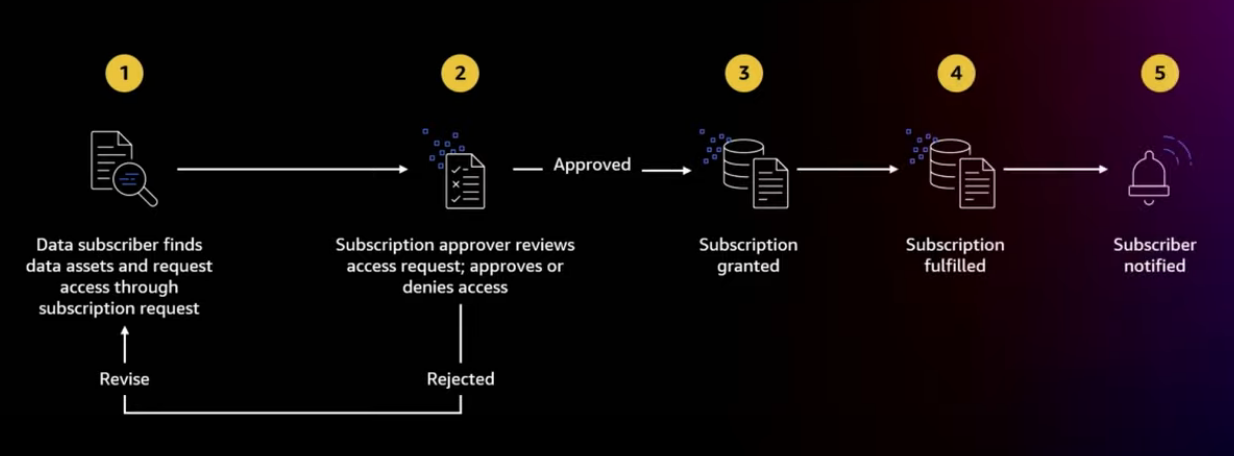
Once the data is publishing to the domain, data consumers can discover and request subscription to it. This process starts by the data subscriber searching and browsing the catalog and to try to find data assets for their use case.
From the Amazon DataZone portal, they can go and type their search term, use the filters and so on. And when they found the assets that they want, they click subscribe and they provide the business justification of, I need this access for so and so.
The subscription approver, as defined in the publishing agreement, can then review the request and decide if the approve or reject.
Once the subscription is granted, a fulfillment process can start to facilitate the access to the data asset for the subscribing project.
The Amazon DataZone can only fulfill a subset of the data asset.
This depends on the type of the data store and the permission provided to the Amazon data zone service.
In our current preview version, the Amazon DataZone supports Lake Formation tables and Redshift tables fulfillment.
[32:31]
Subscription fulfillment for AWS Glue tables
Amazon DataZone supports access control of AWS Lake Formation AWS Glue tables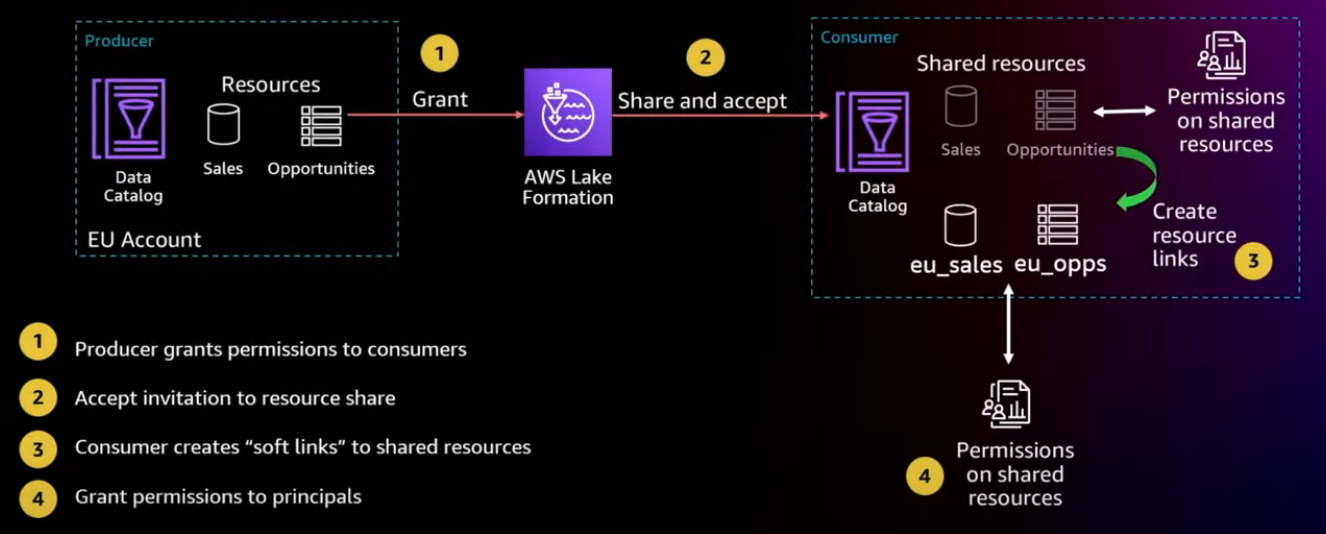
Let's look at those two data stores and see how fulfillment happens for them.
This diagram shows how we implement subscription fulfillment for Lake Formation table using Glue table links, and Lake Formation permissions.
The consumer and the producer can be in completely different accounts and even different regions. There is no need for data movement. There's also no need for an administrator to facilitate each of those subscription. DataZone service can fully automate this process, if provided with the required permissions.
Similarly, for Redshift, again, the consumer and the producer can be in completely different data warehouses. These warehouses might be in different accounts and might be even in different regions. In these cases, we are using the Redshift data shares to facilitate the subscription.
DataZone will orchestrate and maintain the data shares with all the subscribe and granted tables between the producer and the consumer warehouses.
This again, can be done without having a database admin in the middle, completely self-service. Of course, if the consumer and the producer just happen to be on the same data warehouse, this fulfillment can turn into just a simple grant statement.
[34:15]
Discover more about Amazon DataZone
https://aws.amazon.com/datazone/
https://amazondatazone.splashthat.com/
Please let us know if you are interested in joining our preview, which will start early 2023.