The Beauty of S3 Select -- Dramatically Reduce the Processing Time
In this post, we will further illustrate how much we can benefit from S3 Select.
I had briefly compared S3, OSS, and COS in a recent post. In this post, we will focus on Amazon S3 only, deeper dive S3 Selection, and see what we could expect to get the benefit of it.
Before we start, we make a big CSV file of approximately 240 MB. This size is near the maximum uncompressed row group size for S3 Select, which is 256 MB.
After upload that file to S3, we host a piece of Python code in Lambda to observe the time it will take to get the interested row.
Then we create a Lambda function with 1024 MB of Memory and runtime being Python 3.8. This lambda function should have "s3:GetObject" permission for the object you are querying.
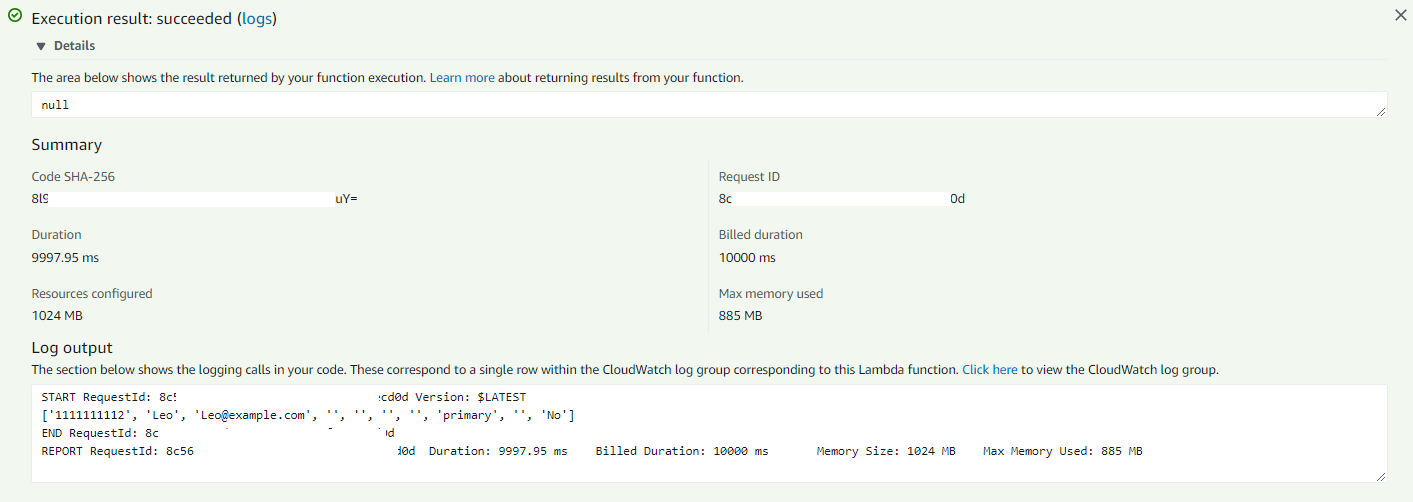
Below Python code would fetch the file to local directory and process the date to find the line with the SSO field as "1111111112".
import json
import boto3
s3 = boto3.client(
's3'
)
def lambda_handler(event, context):
# Download the CSV and handle it locally
# Large size file
s3.download_file(
Bucket='[S3 bucket name]',
Key='object_storage_select_sample_largefile.csv',
Filename='/tmp/object_storage_select_sample_largefile.csv'
)
with open('/tmp/object_storage_select_sample_largefile.csv', "r") as _csv:
csv_lines = _csv.readlines()
csv_lines.pop(0)
for each_line in csv_lines:
items = each_line.replace("\n", "").split(",")
if "1111111112" == items[0]:
print(items)
It took approximately 10 second to complete the data download and processing.
Then we use S3 Select to get the exactly we want. See if there is any performance improvement. Below Python code instruct the S3 service to get the exact data and respond with that piece of data.
import json
import boto3
s3 = boto3.client(
's3'
)
def lambda_handler(event, context):
# Use S3 Select
# CSV
r = s3.select_object_content(
Bucket='[S3 bucket name]',
Key='object_storage_select_sample_largefile.csv',
ExpressionType='SQL',
Expression="select * from s3object s where s.SSO='1111111112'",
InputSerialization = {
'CSV': {
"FileHeaderInfo": "Use"
}
},
OutputSerialization = {
'CSV': {}
},
)
# Handle the response of S3 Select
for event in r['Payload']:
print(event)
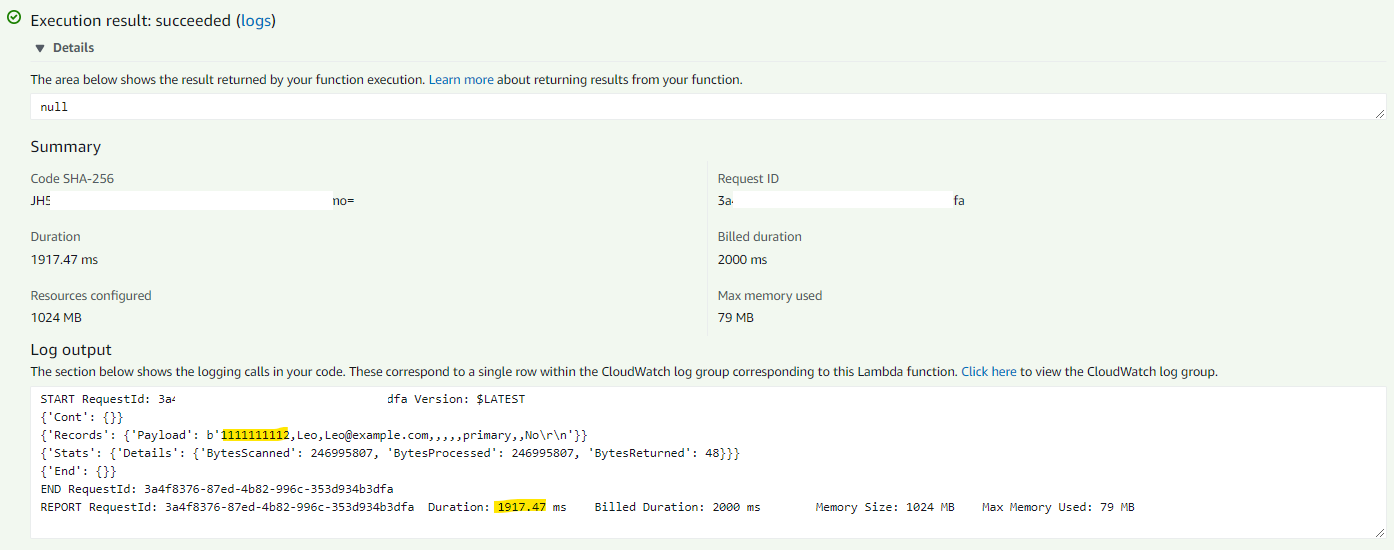
That's it! The whole processing time has been reduced from around 10 seconds to near 2 seconds.
References
Selecting content from objects