AWS re:Invent 2022 -- Keynote with Swami Sivasubramanian
-
As a full-stack cloud architect and an overall enterprise architect of tianzhui.cloud, Swami's keynote must be one of my favorites.
Core elements of a data strategy
- Build future-proof foundations, supported by core data services
- Weave connective tissue, across your organization
- Democratize data, with tools and education
Build a future-proof data foundation
- Tools for every workload
- Performance at scale
- Removing heavy lifting
- Reliability and scalability
Tools for every workload
---
Amazon Athena for Apache Spark (GA[1])
Get started with interactive analytics on Apache Spark under a second
Harness Apache Spark for complex, powerful analytics
Spend more time on insights instead of waiting for results
Build applications without managing resources or configuring software
https://docs.aws.amazon.com/athena/latest/ug/notebooks-spark.html
Amazon Redshift Integration for Apache Spark (GA[1])
Easily run Apache Spark on Amazon Redshift data up to 10x faster than existing Redshift-Spark connectors
Apache Spark runs on AWS: e.g.
- Amazon EMR
- AWS Glue
- Amazon Sagemaker
- Amazon Redshift
- Amazon Athena
Refer to: post
Performance at scale
---
Amazon DocumentDB Elastic Clusters (GA[1])
Fully managed solution to scale document workloads of virtually any size and scale
Elastically scale workloads in minutes
Zero impact to application availability or performance
Automatically manage underlying infrastructure
[26:30-35:10] Expedia Group
Removing heavy lifting
---
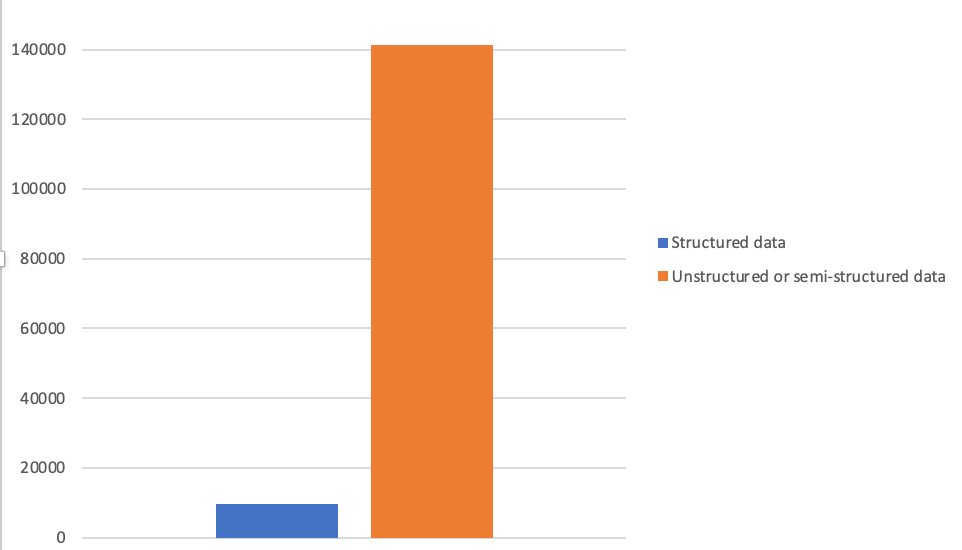
According to Gartner, 80% of all enterprise data is unstructured or semi-structured, including things like images and handwritten notes.
For tianzhui.cloud, this web-site, this number is 94%, much higher than the industry's average.
| Storage type | Size (Mib) | Category |
| S3 | 141144 MiB | Unstructured data |
| RDS | 150 MiB | Structured data |
| DynamoDB | 62 MiB | Semi-structured data |
| OpenSearch | 9510 MiB | Structured data |
Amazon SageMaker supports Geospatial ML (Preview[1])
Making it easier to build, train and deploy machine learning models using geospatial data
Acquire geospatial data with just a few clicks
Easily prepare geospatial data with built-in algorithms
Speed model building with neural network models
[-46:08] demostration
Reliability and scalability
---
Amazon Redshift Multi-AZ - Feature update (Preview[1])
Delivering high availability and reliability to support mission-critical analytics workloads
Guarantees capability to automatically failover
Maximizes price performance with high availability
Maintains business continuity without application changes
Trusted Language Extensions for PostgreSQL - New (GA[1])
A new open-source project to support PostgreSQL extensions on Amazon RDS and Amazon Aurora
Safely use extensions to meet your needs
Install extensions without waiting for AWS certification
Leverage popular programming languages
Amazon GuardDuty RDS Protection - New (Preview[1])
Protect your data in Aurora with intelligent threat detection
Leverages machine learning to accurately detect suspicious activity
Delivers security findings enriched with contextual data
Continuously monitors for potential threats with just one click
Weave connective tissue across your organization
---
AWS Glue Data Quality - Feature update (Preview[1])
Automatically measure, monitor, and manage data quality in your data lake
Generate automatic data quality rules
Enhance data quality for better decision-making
Reduce manual efforts from days to hours
https://docs.aws.amazon.com/glue/latest/dg/glue-data-quality.html
Centralized Access Controls for Redshift Data Sharing - Feature update (Preview[1])
Govern access to Redshift data using AWS Lake Formation
Centrally manage access controls for Redshift data using Lake Formation
Designate user access without complex querying or manual scripts
Enhance security with row-level and column-level data sharing permissions
Amazon SageMaker ML Governance - Feature update (GA[1])
Goverance and auditability for end-to-end ML development
- Role Manager - Define custom user permissions in minutes
- Model Cards - Centralize model information and documentation
- Model Dashboard - Monitor model performance in one place
Amazon DataZone (PS: announced in Adam's keynote?)
Catalog, discover, share, and govern data across the organization
- AWS Lake Formation
- Amazon Athena
- Amazon Redshift Data Sharing
- APIs to third-party sources
[1:06:53 - 1:14:15] demostration
Amazon Aurora zero-ETL integration with Amazon Redshift - Feature update
Amazon Redshift auto-copy from S3 - Feature update (Preview[1])
Simplify and automate file ingestion into Redshift
Easily create and maintain simple data ingestion pipelines
Continuously ingest data as soon as new files are created in S3
Automate data loading without engineering resources
1:21:00
Amazon AppFlow - Move data between SaaS services and data lakes and data warehouses
Amazon AppFlow - Feature update
Amazon AppFlow now offers 50+ connectors
https://aws.amazon.com/about-aws/whats-new/2022/11/amazon-appflow-supports-over-50-connectors/
Amazon SageMaker Data Wrangler - Feature update
Access 40+ new data sources from Amazon SageMaker Data Wrangler
[1:23:47 - 1:31:42] AstraZeneca
Democratize data with tools and education
---
AWS Machine Learning University now provides educator training - Program update (GA)
An AI & ML educator training program for community collegues and MSIs nationwide
- Hands-on training sessions
- Structured curriculum and classroom resources
- Access to an educator community of practice
Amazon QuickSight Q (not announced in this keynote)
Amazon SageMaker Canvas (announced GA on Nov. 30, 2021)
Create ML predictions without any ML experience or writing any code
https://aws.amazon.com/cn/blogs/aws/announcing-amazon-sagemaker-canvas-a-visual-no-code-machine-learning-capability-for-business-analysts/
[1:42:37 - 1:44:25] Warner Bros. Games
-
[1] The GA, Preview and etc. status listed for each feature, product etc. implicates the status with a timestamp of re:Invent 2022, i.e., from Nov. 28 to Dec. 2, 2022.
-