AWS re:Invent 2022 - Enabling agility with data governance on AWS (ANT204)
Agenda
- How does data governance help you become data driven?
- Data governance patterns with AWS analytics services
- Prudential Financial Services data journey
[0:53]
Data driven themes we hear from customers
The transformation is challenging, requiring a strong vision, new culture, skills, and technology
- Understanding what "great looks like"
- Identifying and prioritizing use cases
- Creating sponsorship & business case
- Creating a data-driven culture
- Gaps in skills and technologies
- Data privacy, security, compliance, and governance
[]
Data governance is essential to being data driven
[3:30]
Definition
Data governance is the collection of policies, processes, and systems that organizations use to ensure the quality and appropriate handling of their data throughout its lifecycle for the purpose of generating business value
(Amazon's definition)
[4:14]
Data governance starts with business
Business strategy / business challenges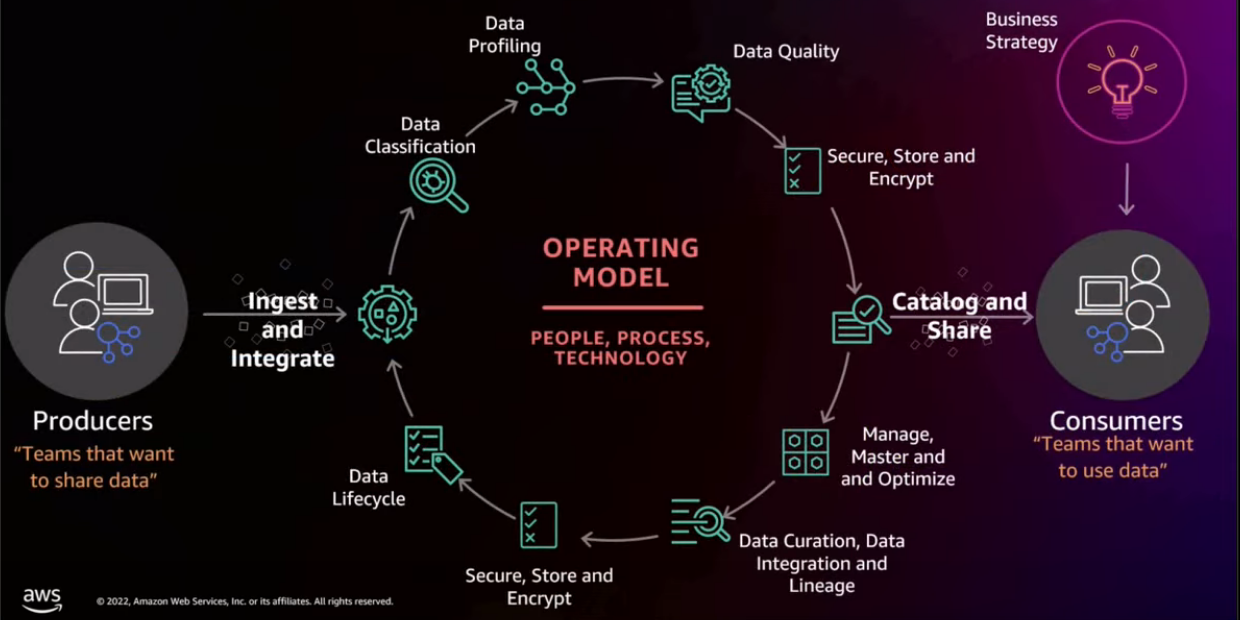
The first thing you want to do is tie it to your business strategy.
Schema-on-read's an interesting concept, because you definitely wanna just put the data in and people can get value really quickly.
The bottom part of the slide is once data is in the hand of consumers, they can manage that data, they can create new data sets, they can then become producers on their own. So if you think about a consumer in that point in time, they might be using data, accessing, querying, making decisions.
They don't just make a decision and it goes away.
They want to create something new to share with their executives, share with their business partners. That's where they actually become a producer and they're gonna be data curating, data integration, building lineage, securing that data and start and continuing that life cycle of data throughout. So how do AWS services help?
Data curation is the process of creating, organizing and maintaining data sets so they can be accessed and used by people looking for information.
https://www.techtarget.com/searchbusinessanalytics/definition/data-curation
[8:08]
How do AWS services help?
[8:14]
Data governance across the data pipelines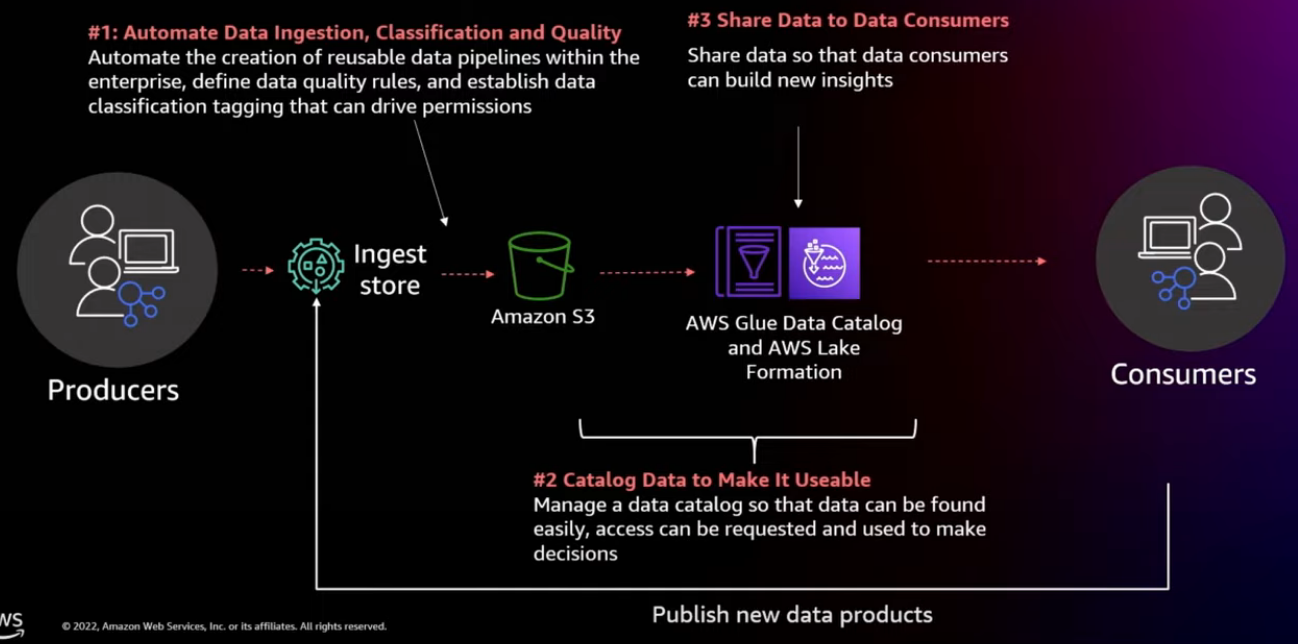
[8:48]
Automate data governance on ingestion
Challenges need to be handled:
| Automate Ingestion Pipelines |
Inconsistent Performance, Reusability, and Quality |
Complying with Regulations |
|
|
|
So as you're monitoring your data quality, you're running data profiling, you look at the data, you inspect the data, and use things like machine learning such as Glue as PII detection. Then there's Macie for example, Comprehend can do some PHI detection as well. How do you automate that as part of a pipeline, and then classify that data on the way in, and carry it through your environment?
[11:02]
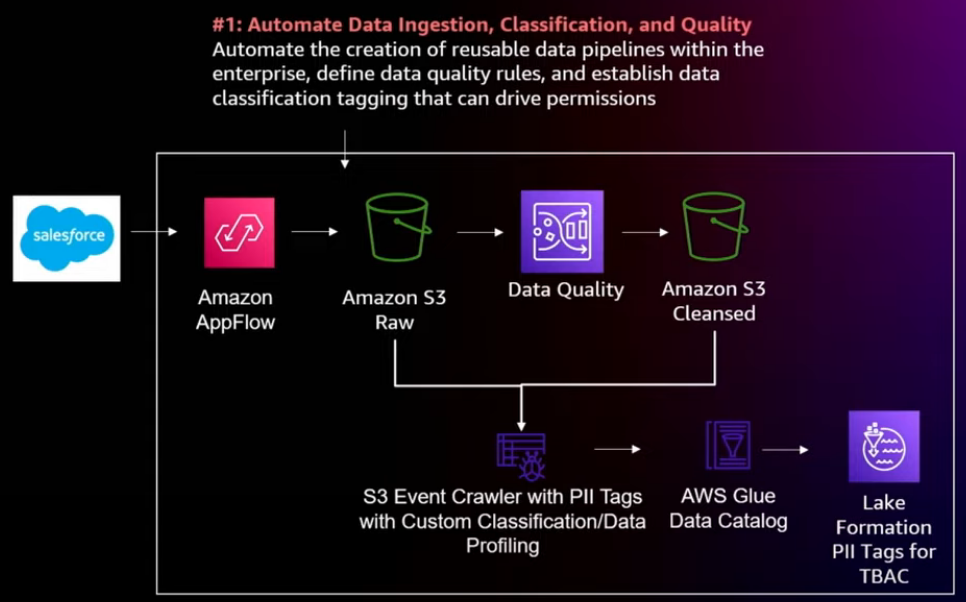
Example automation data ingestion & store
- Data classification
- Data profiling
- Data quality
- Secure, store, and encrypt
- Catalog
- AWS Data Ops Development Kit (AWS CDK)
[12:19]
Catalog your data for findability
[12:36]
Crawl datasets to remove heavy lifting
Crawlers data sources:
Amazon S3
Amazon DynamoDB
Delta Lake
Amazon Redshift
Amazon Aurora
MariaDB
Microsoft SQL Server
MySQL
Oracle
PostgreSQL
MongoDB
Amazon DocumentDB
Snowflake DB (New)
Additional Catalog w/o Crawlers (catalogs that aren't covered by crawlers)
AWS CloudTrail
Kafka
And others…

Crawlers - Automatically discover new data and extract schema definitions
Detect schema changes and maintain tables, determine partitions on Amazon S3
Use built-in classifiers for popular data types such as PII or create your own custom classifier using Grok expressions
Profile data to share table statistics through a single catalog (New)
Run on demand, incrementally, on a schedule, on an event, or catalog data built in AWS Glue or Amazon AppFlow (New)
AppFlow is not a crawler feature but a catalog feature.
Let's say our business case is customer analytics and I need to identify PII, you can then apply that first PII rule to other data sets that might have customer data in it, and leverage that over time.
[15:17]
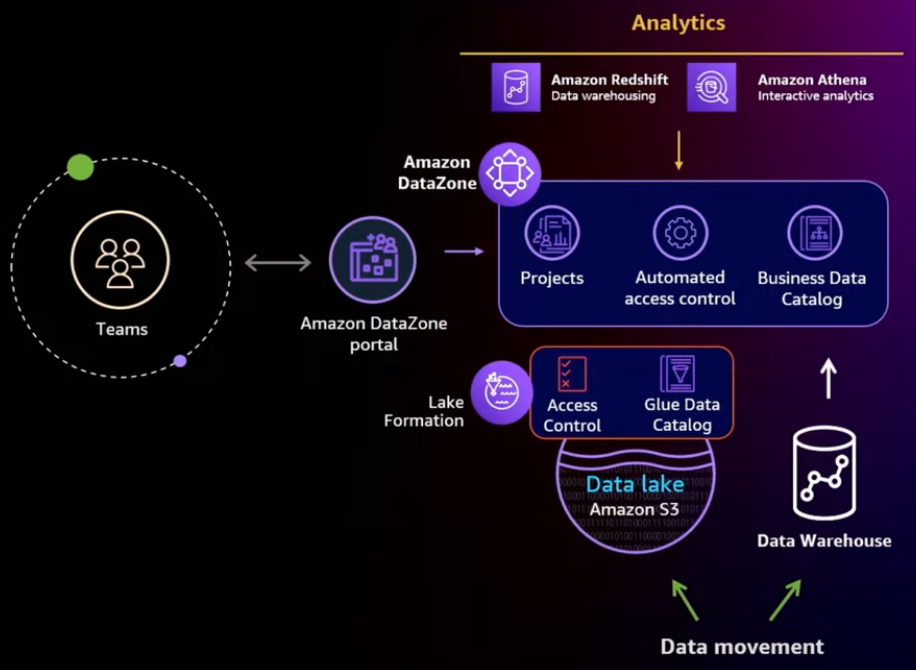
Amazon DataZone extends the AWS Analytics stack
What about business catalog here? Amazon DataZone is a new service that enables customers to discover and share data across your organizational boundaries, lines of businesses with built in governance access controls.
- Organization-wide business data catalog
- Governance and access control
- Simplified access to analytics
- Data portal
[17:13]
Share your data easily
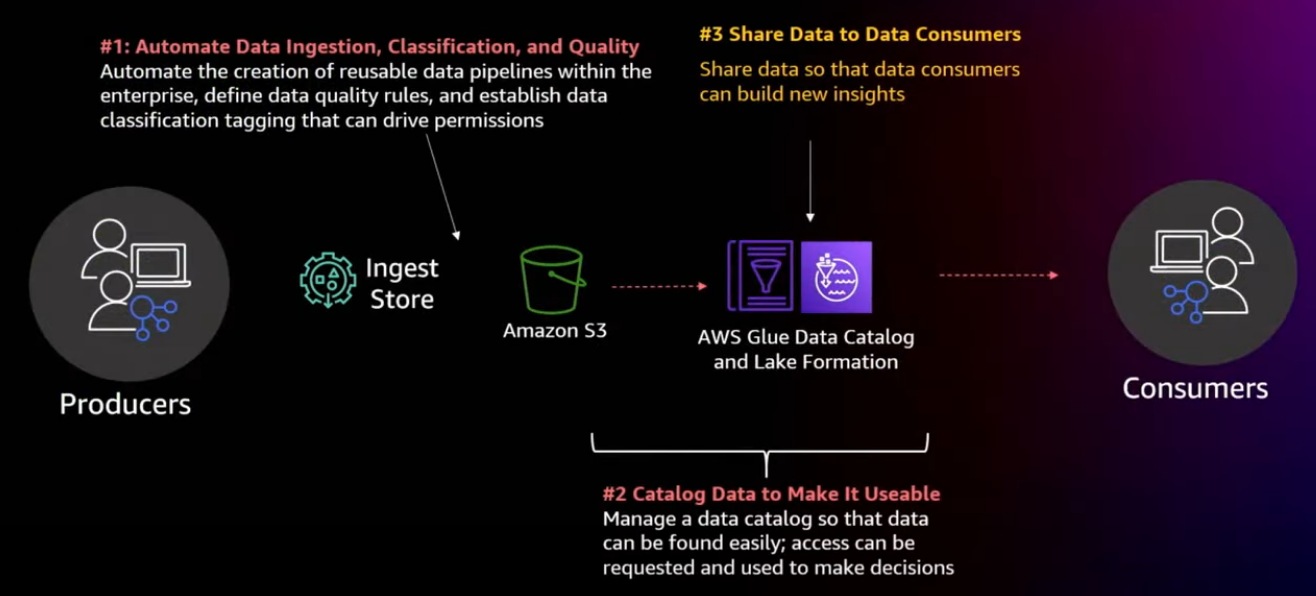
[17:32]
Simple data sharing with Lake Formation

[18:24]
Lake Formation permissions model

- DB-style fine-grained permissions on resources
- Scale permissions management Lake Formation Tag-Based Access Control (LF-TBAC): moving from resource based access controls, managing your tables based on your user community, to tags which are focused more of your energy on like what data sets they are and how do I scale giving people access to that data set, based on what they are and what classification rules they provide.
- Unified Amazon S3 permissions
- Integrated with services and tools
- Easy to audit permissions and access
[19:25]
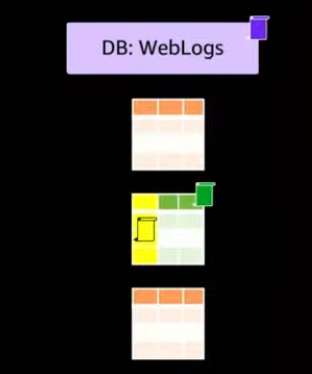
Leverage Lake Formation TBAC to scale permissions
| Define LF-Tags | Assign LF-Tags to resources | Create policies on LF-Tags |
 |
 |
 |
|
|
|
Moving your access control permissions to tags.
The first thing you want to do is define your tag ontology. So your tag ontology could be things like organizational structure, or classification rules.
The next thing you do is you apply those tags to catalog resources, databases, tables. The higher you apply the tag, the more predominant the access is given. So you could provide it at the database level, for example. They're hierarchical nature and if there are conflicts, the system resolves those conflicts.
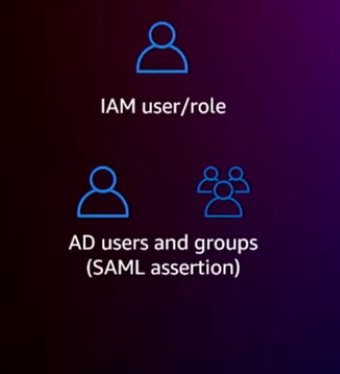
The last thing is you create those policies on those Lake Formation tags, for IAM users and roles, and active directory users and groups, using SAML assertions.
That's how you scale your access permission.
Let's put this in context to your architecture.
[20:50]
Automate data sharing
An open approach to data sharing
Data Consumer
- Enable personas to discover, understand, consume, and request access
- Abstract complexity through automation
- Enforce governance through data classification built into LF Tags
- Extend data marketplace capabilities to third-party catalogs

There's open source solutions like data.all, for example.
... access down to your data domains. It could be your S3 data lake or Redshift for that example.
[22:36]
Key takeaways
- Automate ingestion pipelines and include compliance controls, standard data quality rules so data engineers can move at the speed of business
- Automate cataloging, classifying, profiling your data through crawlers and make that data available via a business catalog
- Automate the management of tag-based access control to ensure data is protected through the data lifecycle
- Automate sharing of data so users in one interface can find the data they want and immediately start working with it
[24:05]
Prudential
[52:40]
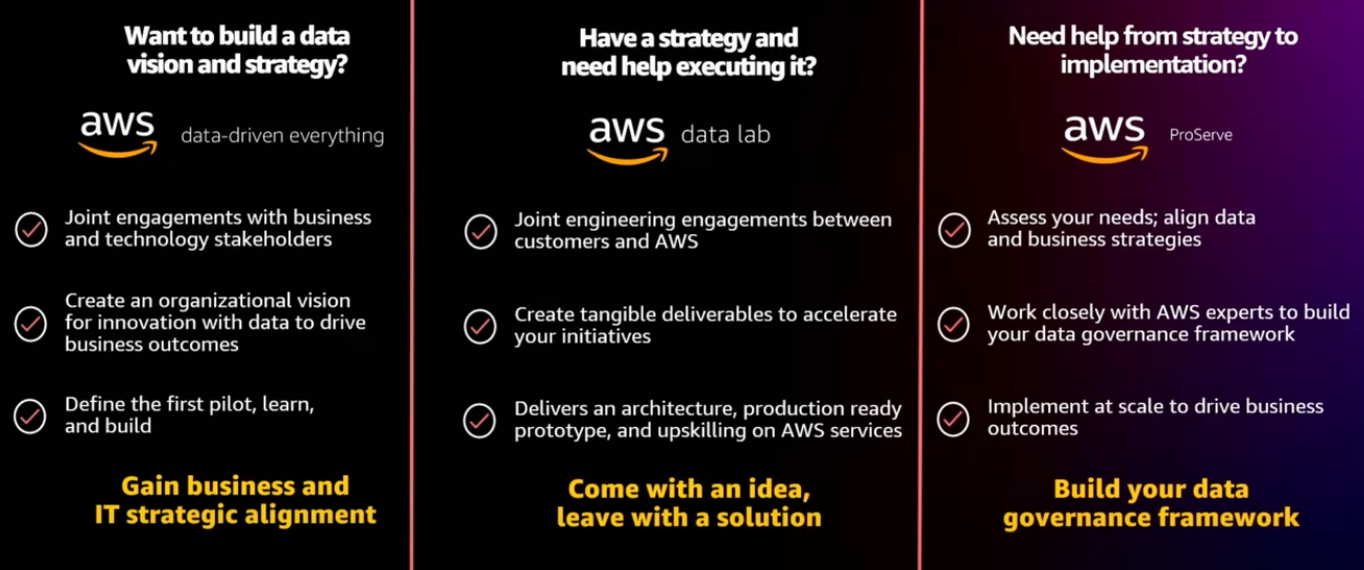
AWS programs that support data governance
[53:15]
Getting started: Next steps
- Think big
- Discover Workshop
- Data-Driven Everything
- Start small
- Data Labs
- AWS ProServe POC
- Scale fast
- AWS ProServe
- AWS Partners
-