Amazon Redshift Integration with Apache Spark
This feature is annouced on re:invent 2022. This blog post is a follow up of the leading post.
This integration provides connectivity to Amazon Redshift and Amazon Redshift Serverless.
Amazon Redshift integration for Apache Spark builds on an existing open source connector project (GitHub spark-redshift-community / spark-redshift) .
AWS Glue 4.0 come with the pre-packaged connector and JDBC driver, and you can just start writing code.
When you use AWS Glue 4.0, the spark-redshift connector is available both as a source and target. In Glue Studio, you can use a visual ETL job to read or write to a Redshift data warehouse simply by selecting a Redshift connection to use within a built-in Redshift source or target node.
Create Amazon Redshift resource. Here I used Redshift Serverless for demonstration.
目前版本的Glue Studio不能自动发现Serverless的Redshift URL。创建Connection,更新JDBC URL。(不排除CLI的方式可行)
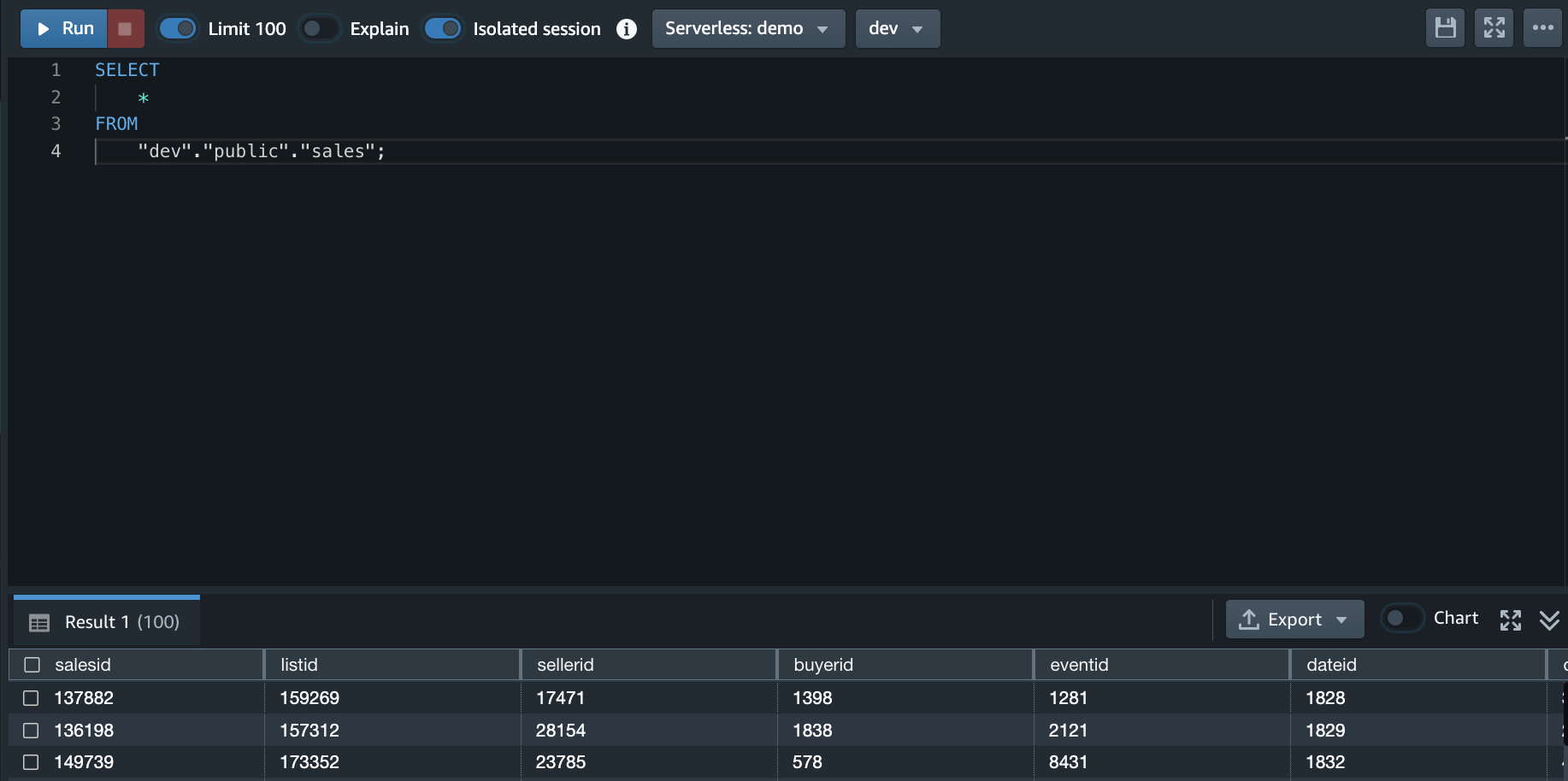
Source table
创建sales table。做为后面ETL的source。
create table sales( salesid integer not null, listid integer not null distkey, sellerid integer not null, buyerid integer not null, eventid integer not null, dateid smallint not null sortkey, qtysold smallint not null, pricepaid decimal(8,2), commission decimal(8,2), saletime timestamp);
Load data from S3 into Redshift.
copy sales from 's3://<****>-us-west-2/tickit/sales_tab.txt' iam_role 'arn:aws:iam::<111122223333>:role/myRedshiftRole' delimiter '\t' timeformat 'MM/DD/YYYY HH:MI:SS' region 'us-west-2';
Target table
基于这个场景,Glue貌似(不排除CLI的方式可行,有待进一步验证)只支持external的Data Catalog DB作为target。所以首先在Redshift中create external schema,这里命名为“spectrum”。做为后面ETL的target。
create external schema spectrum from data catalog database 'spectrumdb' iam_role 'arn:aws:iam::<111122223333>:role/myRedshiftRole' create external database if not exists;
创建另一个结构相同的sales表.
create external table spectrum.sales(
salesid integer,
listid integer,
sellerid integer,
buyerid integer,
eventid integer,
dateid smallint,
qtysold smallint,
pricepaid decimal(8,2),
commission decimal(8,2),
saletime timestamp)
row format delimited
fields terminated by '\t'
stored as textfile
location 's3://<****>-us-west-2/tickit/spectrum/sales_glue_spark_redshift/'
table properties ('numRows'='172000');
新的Table里面是空的。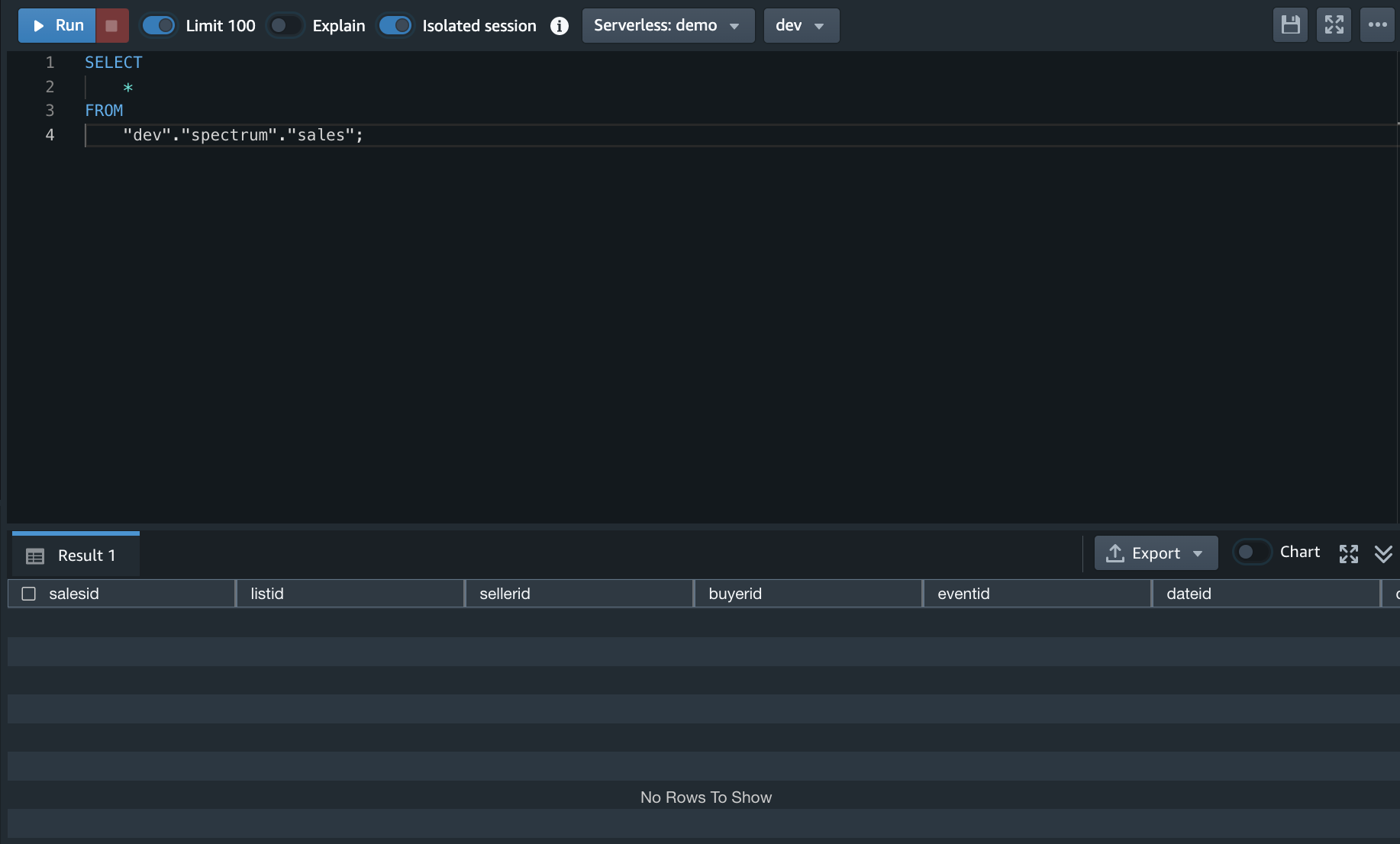
Glue
To get started, choose Jobs in the left menu of the Glue Studio console. Using either of the Visual modes, you can easily add and edit a source or target node and define a range of transformations on the data without writing any code.
Choose Create and you can easily add and edit a source, target node, and the transform node in the job diagram. At this time, you will choose Amazon Redshift as Source and Target.
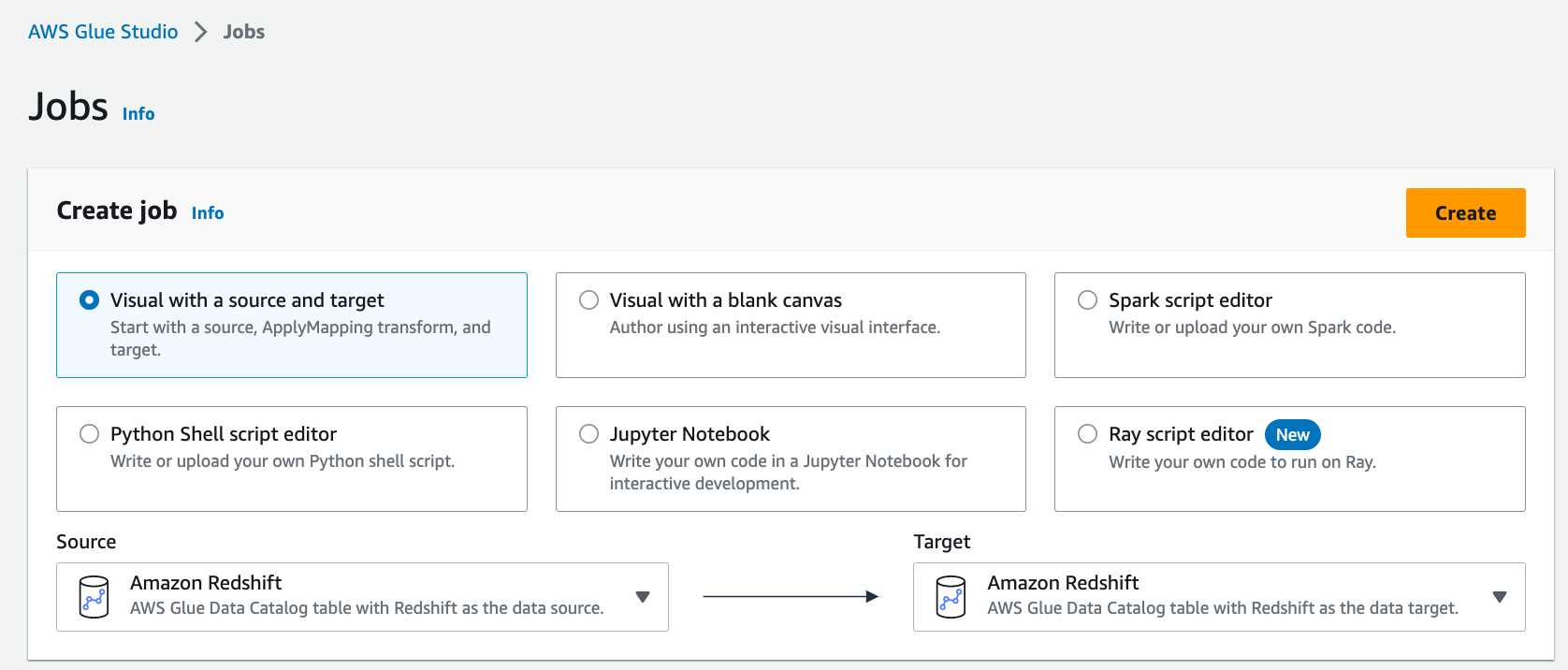
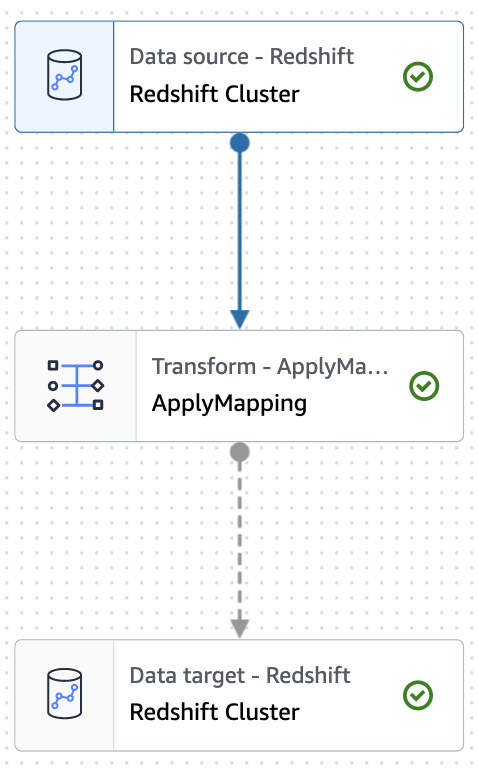
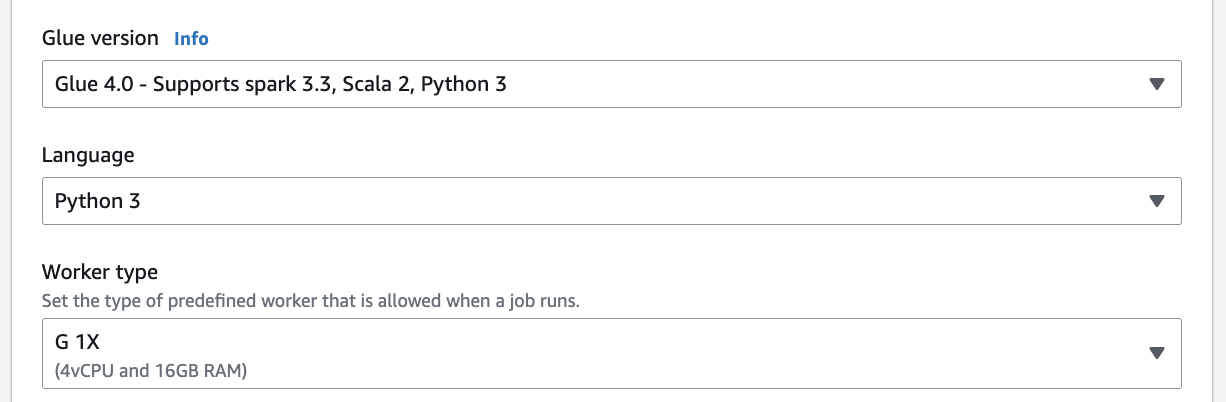
Currently, you can only use version 3.3.0 of Spark with this integration. When you set up your job detail, you can only use the Glue 4.0 – Supports spark 3.3 Python 3 version for this integration.
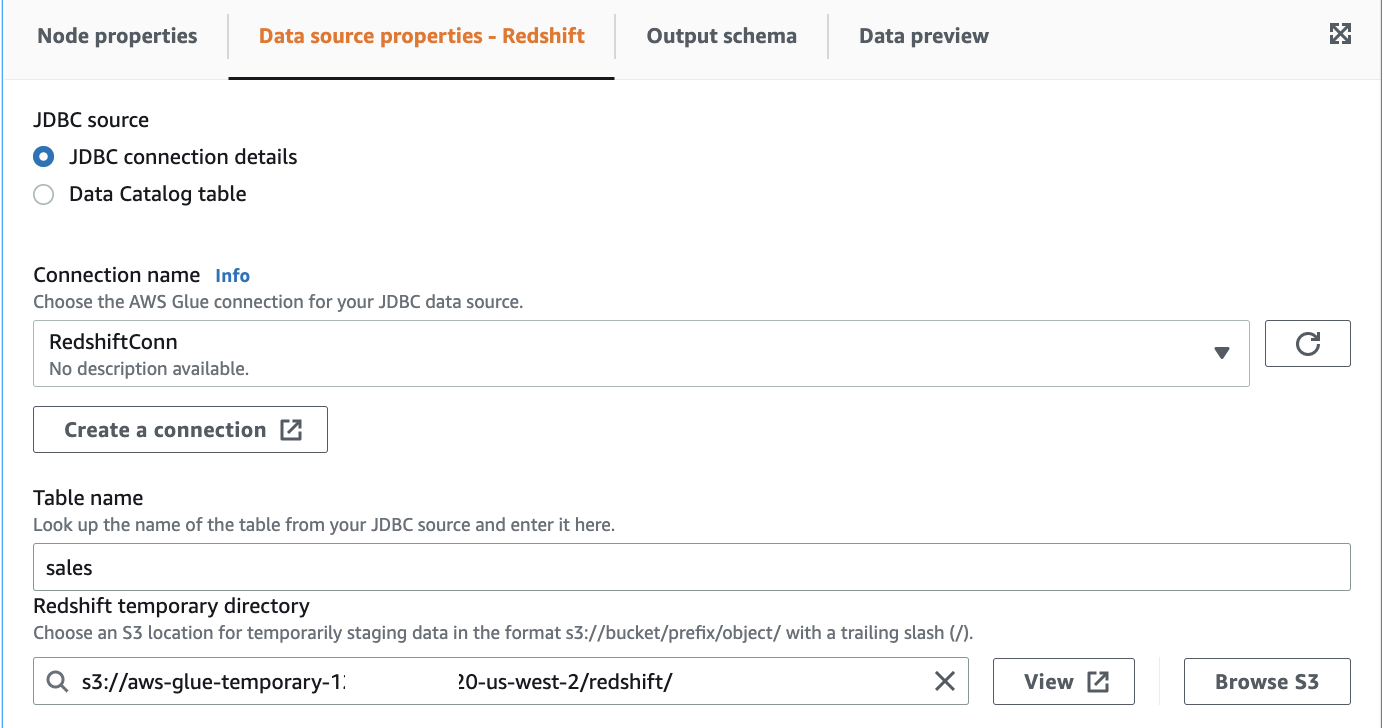
Data Source: Redshift
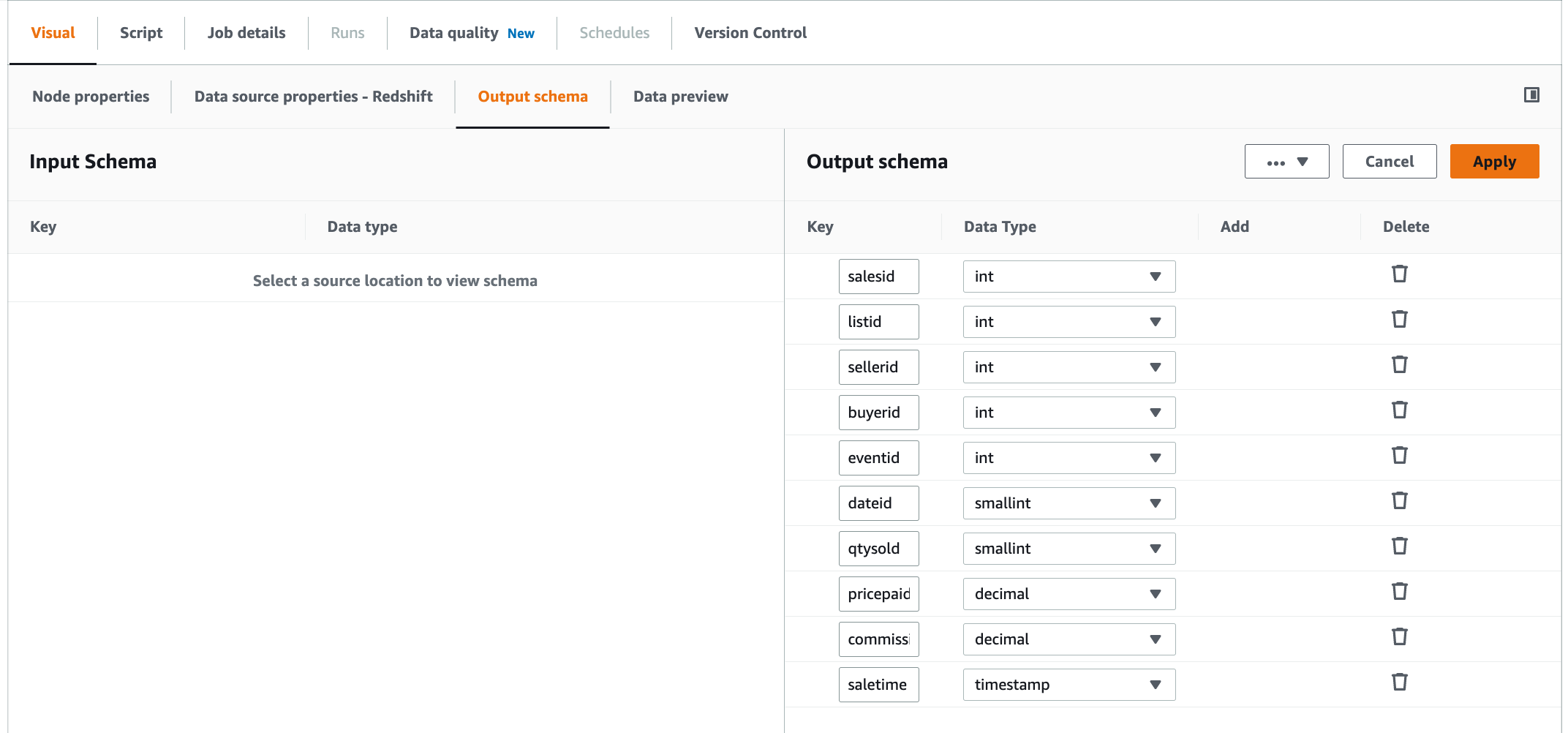
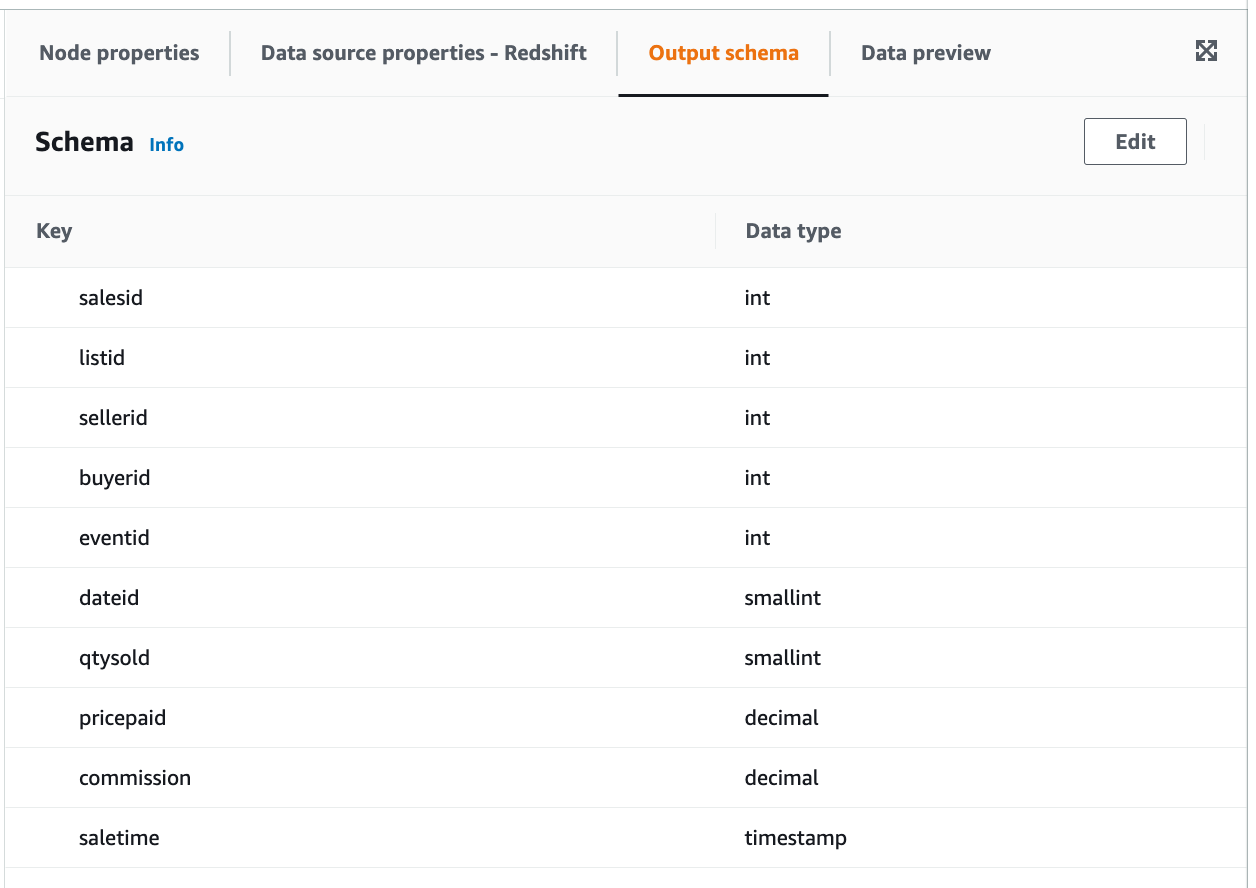
Click Apply.
Transform
Transform保持默认,本post不做任何实际的transformation。
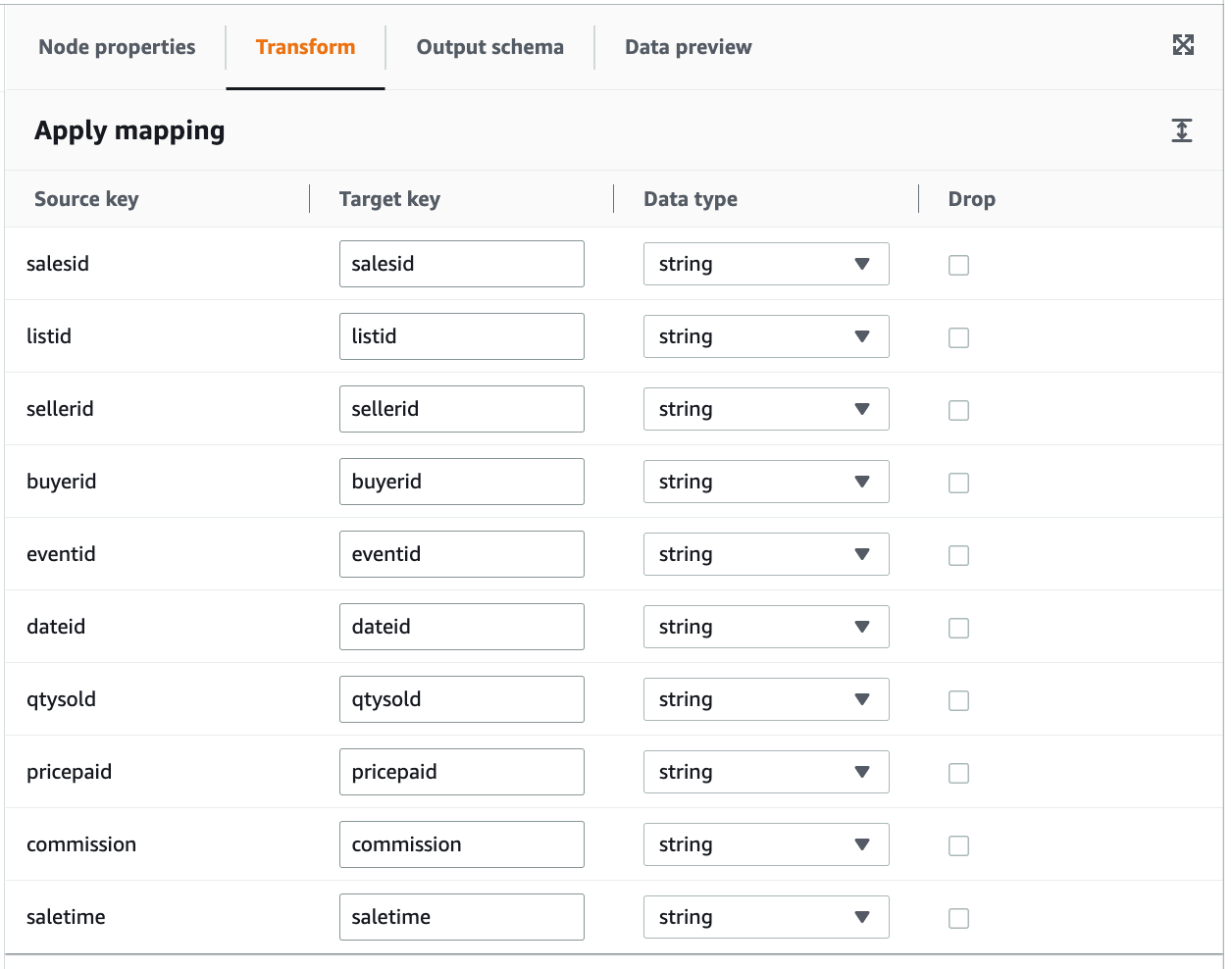
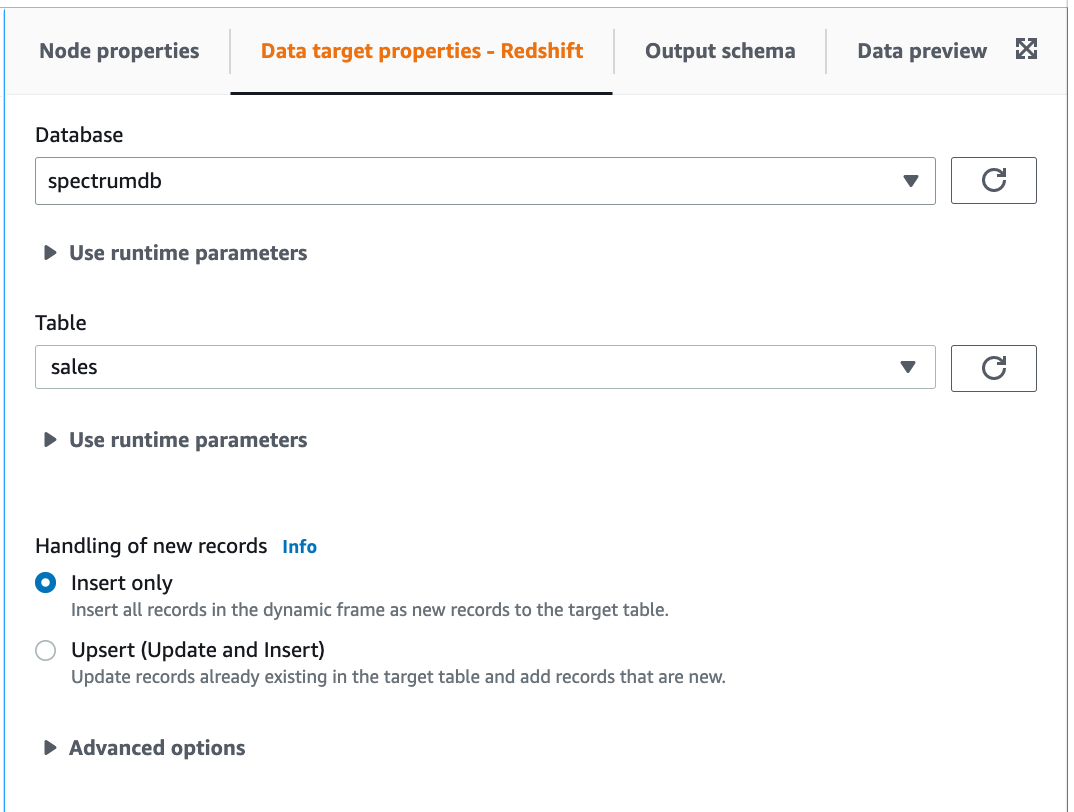
Data Target: Redshift
Security group:
The SG should have one inbound rule that allows incoming traffic from within the same SG and allows all ports.
Run Glue job.
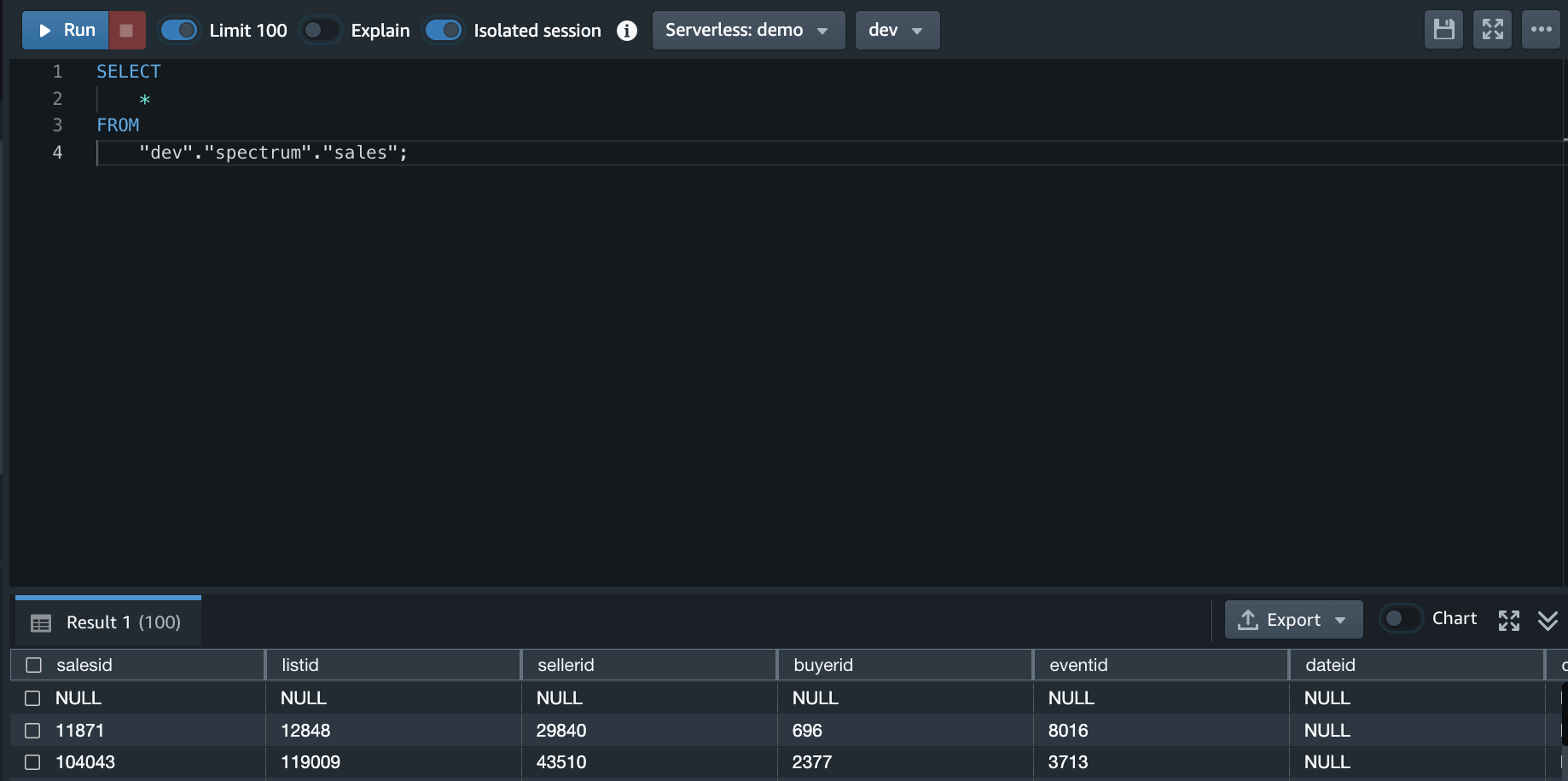
Appendix
Generated script
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.dynamicframe import DynamicFrame
def directJDBCSource(
glueContext,
connectionName,
connectionType,
database,
table,
redshiftTmpDir,
transformation_ctx,
) -> DynamicFrame:
connection_options = {
"useConnectionProperties": "true",
"dbtable": table,
"connectionName": connectionName,
}
if redshiftTmpDir:
connection_options["redshiftTmpDir"] = redshiftTmpDir
return glueContext.create_dynamic_frame.from_options(
connection_type=connectionType,
connection_options=connection_options,
transformation_ctx=transformation_ctx,
)
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
# Script generated for node Redshift Cluster
RedshiftCluster_node1 = directJDBCSource(
glueContext,
connectionName="RedshiftConn",
connectionType="redshift",
database="dev",
table="sales",
redshiftTmpDir="s3://aws-glue-temporary-<111122223333>-us-west-2/redshift/",
transformation_ctx="RedshiftCluster_node1",
)
# Script generated for node ApplyMapping
ApplyMapping_node2 = ApplyMapping.apply(
frame=RedshiftCluster_node1,
mappings=[
("salesid", "int", "salesid", "string"),
("listid", "int", "listid", "string"),
("sellerid", "int", "sellerid", "string"),
("buyerid", "int", "buyerid", "string"),
("eventid", "int", "eventid", "string"),
("dateid", "smallint", "dateid", "string"),
("qtysold", "smallint", "qtysold", "string"),
("pricepaid", "decimal", "pricepaid", "string"),
("commission", "decimal", "commission", "string"),
("saletime", "timestamp", "saletime", "string"),
],
transformation_ctx="ApplyMapping_node2",
)
# Script generated for node Redshift Cluster
RedshiftCluster_node3 = glueContext.write_dynamic_frame.from_catalog(
frame=ApplyMapping_node2,
database="spectrumdb",
table_name="sales",
redshift_tmp_dir=args["TempDir"],
transformation_ctx="RedshiftCluster_node3",
)
job.commit()
References
New – Amazon Redshift Integration with Apache Spark
Amazon Redshift integration for Apache Spark